Performance Tuning for Single-table Queries
Dec 23, 2023
Read in 4 minutes
Introduction
In our previous article, we have shown that Hive on MR3 1.7 runs much faster than Spark 3.4.0 on the TPC-DS benchmark with a scale factor of 10TB (7415 seconds vs 19669 seconds). The performance gap is expected to widen further due to improvements in Hive on MR3 1.8 (6867 seconds vs 7415 seconds). Still, however, there is a category of queries on which Hive on MR3 seems noticeably slower than Spark: single-table queries with no joins.
Recently a user of Hive on MR3 challenged us with the goal of making Hive on MR3 run faster than Spark on such single-table queries. We were provided with a sample query – a short yet prevalent type among BI analysts:
SELECT shop_id, partner, COUNT(DISTINCT unique_id)
FROM trade_record
GROUP BY shop_id, partner;
The table trade_record comprises 62 columns
and holds 9.7 billion (9,769,696,688) records,
totaling 3.3TB of data.
A particular characteristic of the table trade_record is that
the key unique_id is not unique in every record
and has 5.4 billion (5,361,347,747) distinct values:
> SELECT COUNT(DISTINCT unique_id) FROM trade_record;
5361347747
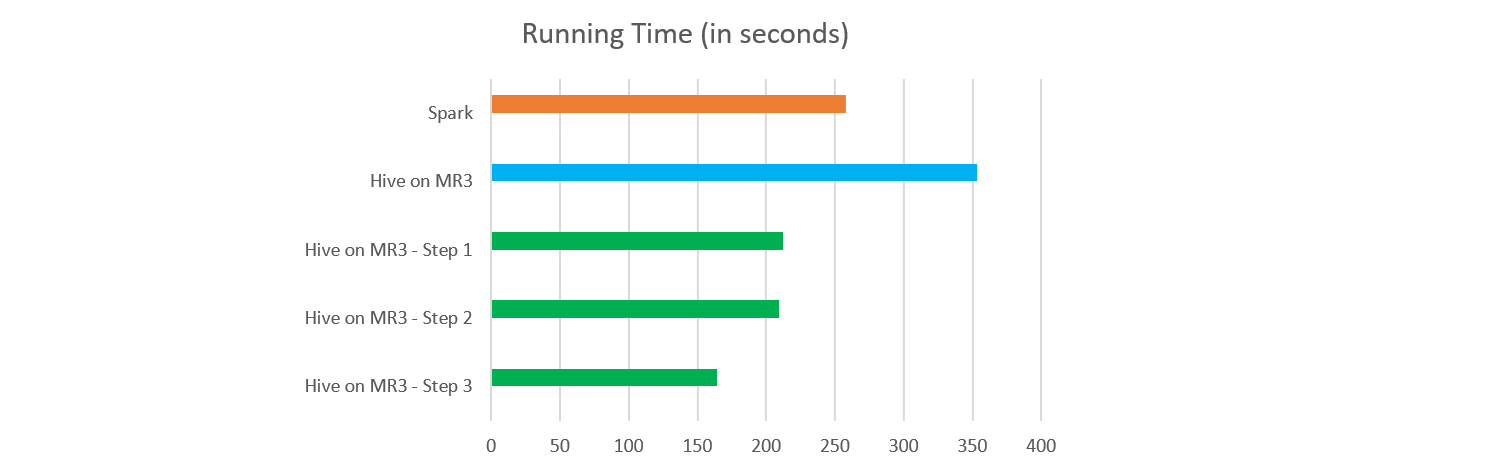
For the sample query, the user reports that Spark runs faster than Hive on MR3 where both systems are allocated the same amount of resources (32 Executors/ContainerWorkeres, each with 46GB of memory) in the same cluster and use Java 8:
- Spark 3.4.1: 258.076 seconds
- Hive on MR3 1.8: 363.49 seconds
This article provides details of our analysis, including how to adjust configuration parameters of Hive on MR3. In the end, Hive on MR3 outperforms Spark, completing the sample query in 163.91 seconds.
Step 1 - Split a reduce vertex into two
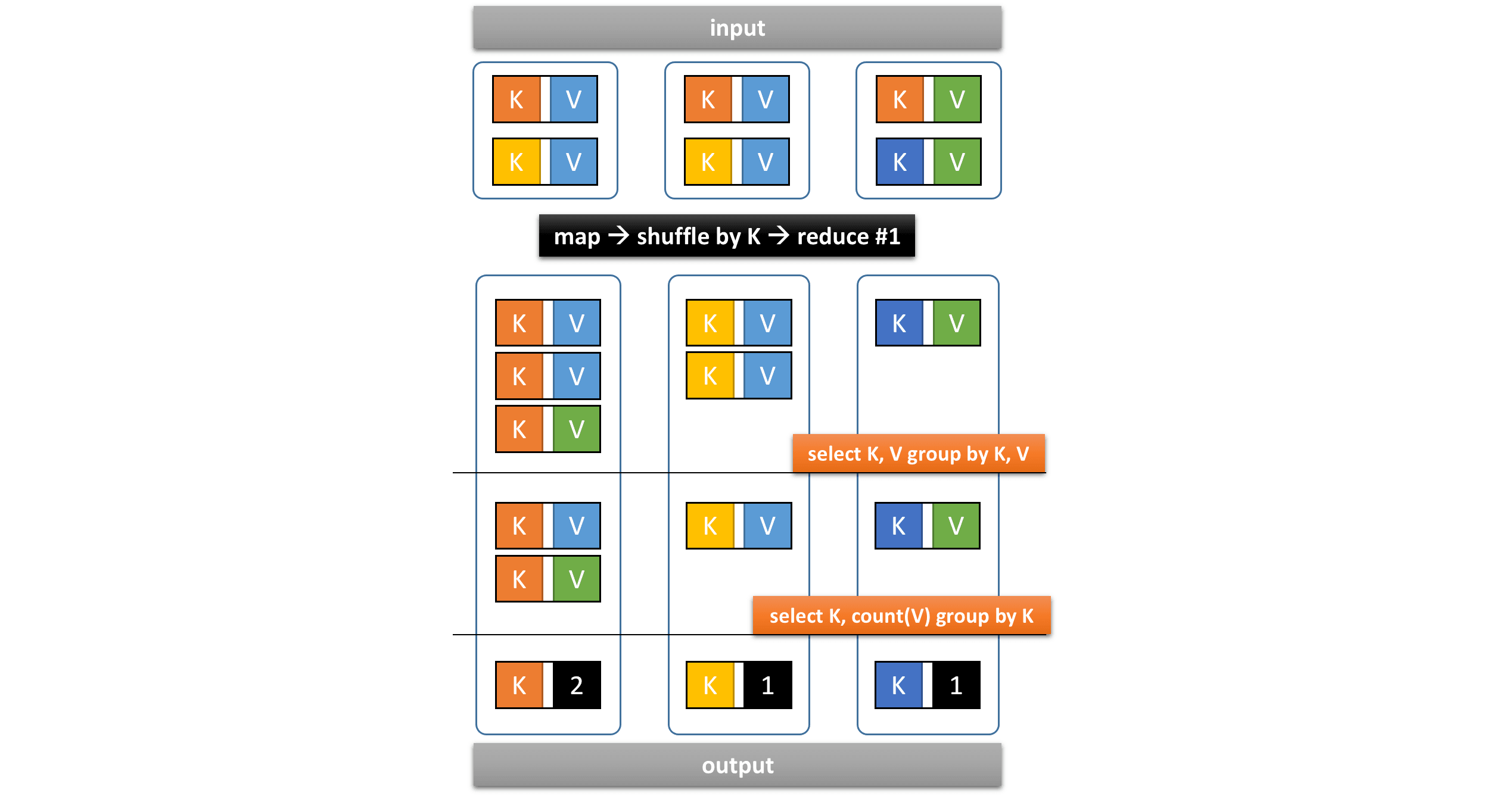
Our initial analysis shows that
Hive on MR3 produces
a single reduce vertex which calculates the final result at once.
In the following diagram, the key K corresponds to (shop_id, partner)
and the value V corresponds to unique_id:
In contrast, Spark generates two reduce vertexes and performs shuffling twice, first by K, V and second by K:
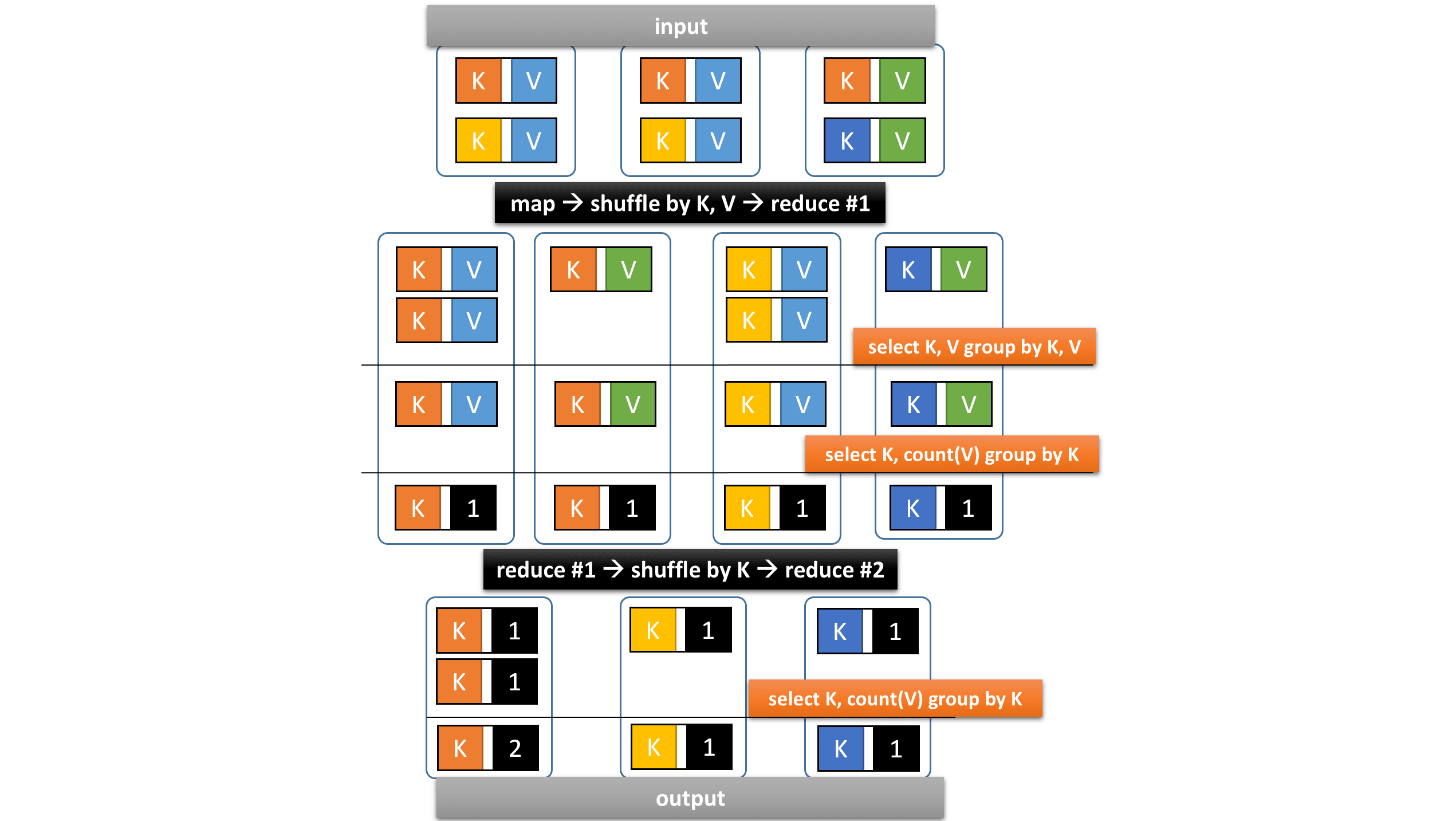
As a result,
Hive on MR3 performs shuffling only once,
but the the heavy computation in reduce tasks becomes the performance bottleneck.
In order to split the reduce vertex into two
and obtain the same query plan produced by Spark,
we make the following change in hive-site.xml:
- set
hive.optimize.reducededuplicationto false
After the change in the configuration, Hive on MR3 completes the query in 211.87 seconds, thus slightly faster than Spark.
Step 2 - Skip merging ordered records
For a vertex producing ordered records,
Hive on MR3 can perform merging before shuffling to downstream vertices.
This feature, not found in Spark,
has the potential to greatly reduce the execution time of shuffle-intensive queries.
As it is not useful for the sample query,
we disable this feature with the following changes in tez-site.xml:
- set
tez.runtime.pipelined-shuffle.enabledto true - set
tez.runtime.enable.final-merge.in.outputto false
Despite these changes, the execution time barely varies, and Hive on MR3 completes the query in 209.00 seconds.
Step 3 - Enable memory-to-memory merging
As the last step, we enable memory-to-memory merging in reduce tasks.
By default, Hive on MR3 performs disk-based merging
to merge ordered records shuffled from upstream vertices.
For the sample query,
the number of ordered records to be merged in each reduce task is small,
so memory-to-memory merging can be particularly effective.
We make the following changes in tez-site.xml:
- set
tez.runtime.optimize.local.fetchto false - set
tez.runtime.shuffle.memory-to-memory.enableto true - set
tez.runtime.task.input.post-merge.buffer.percentto 0.9 (or any value close to 1.0)
After these changes in the configuration, Hive on MR3 completes the query in 163.91 seconds, thus clearly faster than Spark. The following graph summarizes the experimental results:
Conclusion
Hive on MR3 makes efficient use of memory to store intermediate data
and provides additional configuration keys to enhance memory utilization,
much like Spark.
For example, the following log reveals that
the execution of query 4 in the TPC-DS benchmark with a scale factor of 10TB
transmits approximately 410GB (441,155,425,862 bytes) of intermediate data during shuffling,
all of which is stored in memory and never spilled to local disks,
as indicated by SHUFFLE_BYTES_TO_DISK:
2023-12-23T11:56:21,492 INFO [HiveServer2-Background-Pool: Thread-112] mr3.MR3Task: SHUFFLE_BYTES_TO_MEM: 441155425862
2023-12-23T11:56:21,492 INFO [HiveServer2-Background-Pool: Thread-112] mr3.MR3Task: SHUFFLE_BYTES_TO_DISK: 0
Moreover Hive on MR3 offers a configuration key to store intermediate data in spare memory in workers, further maximizing memory utilization. In all aspects, Hive on MR3 leverages in-memory computing no less than Spark.
So, should we update the default configuration of Hive on MR3 as suggsted in this article? Our answer is that it depends. For example, enabling memory-to-memory merging accelerates some queries of the TPC-DS benchmark, but also fails a few shuffle-intensive queries. On the other hand, it may be a good idea to enable memory-to-memory merging in an environment where only simple queries are executed.
We thank GitHub user BsoBird for running all the experiments reported in this article.
If you are interested in Hive on MR3, see Quick Start Guide.