Hive on MR3 - from Java 8 to Java 17 (and beating Trino)
Dec 9, 2023
Read in 4 minutes
Introduction
Before MR3 1.8, Hive on MR3 was built with Java 8. From MR3 1.8, we release Hive on MR3 built with Java 17 as well. An immediate benefit of upgrading to Java 17 is a significant improvement in speed and stability. In this article, we compare the performance of 1) Hive on MR3 from the initial release 1.0 to the latest release 1.8, and 2) Hive on MR3 1.8 with Java 8 and with Java 17. We also compare Hive on MR3 1.8 and Trino 418.
Experiment Setup
For experiments, we use a cluster consisting of 1 master and 22 worker nodes with the following properties:
- 2 x Intel(R) Xeon(R) X5650 CPUs
- 96GB of memory
- 6 x 500GB HDDs
- 10 Gigabit network connection
In order to evaluate the performance of Hive on MR3, we use query 4 of the TPC-DS benchmark with the scale factor of 1TB. Query 4 is a good choice for our experiments because it is shuffle-intensive and generates both unordered and ordered data, with 21 vertexes and 30 edges in its DAG plan.
We repeat to execute query 4 a total of 50 times and report the sum of running times as well as
the their geometric mean.
We use the same set of configuration parameters across all the versions of Hive on MR3.
We use the same options for both Java 8 and Java 17 (with -XX:+UseG1GC),
except that Java 8 uses an extra option -XX:+AggressiveOpts.
Result
For the reader's perusal, we attach the table containing the raw data of the experiment results. Here is a link to [Google Docs].
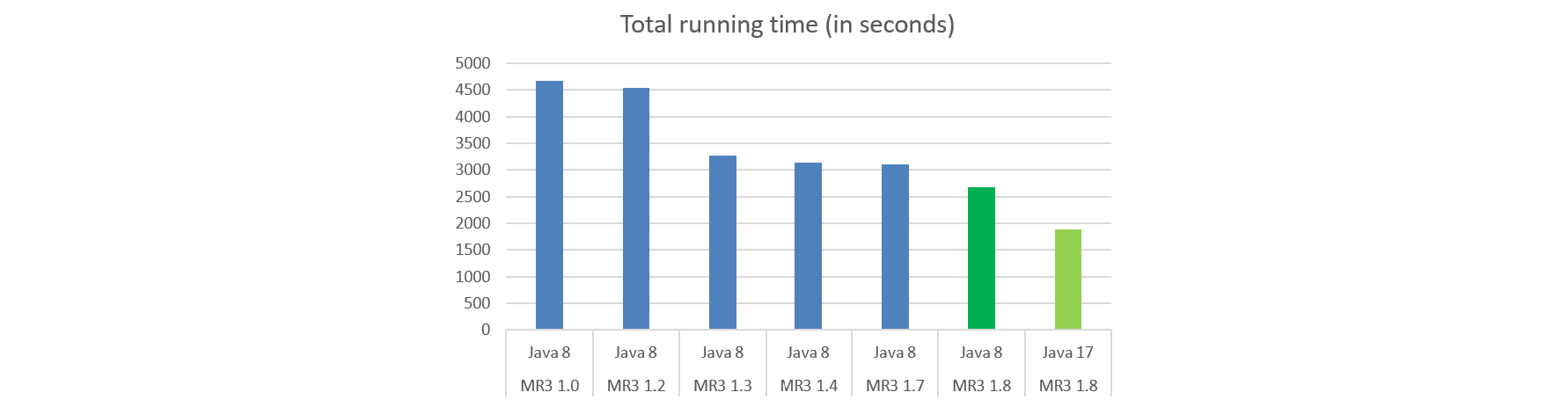
The following graph shows the total running time of each run.
Analysis
#1. From MR3 1.0 to MR3 1.8
We observe that as MR3 evolves from 1.0 to 1.8, the running time of Hive on MR3 continues to decrease and Hive on MR3 1.8 ends up being 1.75 times faster than Hive on MR3 1.0 (2675 seconds vs 4673 seconds). In particular, the running time decreases sharply with MR3 1.3, which is mainly due to the optimization implemented in HIVE-20702.
Although HIVE-20702 is critical for the performance improvement in MR3 1.3, it also brings a new stability problem which is manifested as a drop in performance after Hive on MR3 executes many queries. The drop in performance is caused by an inefficient use of native memory in Java 8 (not by memory leak in Java heap). This problem disappears when we build Hive on MR3 with Java 17.
#2. From Java 8 to Java 17
When we upgrade from Java 8 to Java 17, the total running time decrease from 2675 seconds to 1882 seconds, thus achieving a reduction of 30 percent. The stability problem found in Java 8 also disappears altogether. Considering the maturity of Hive, we think that this is a major improvement (provided for free) in performance which would not be easy to achieve with any additional optimization techniques in Hive.
Conclusion
As Hive on MR3 with Java 17 is no more difficult to run than with Java 8, the default setting in MR3 1.8 now assumes Java 17. For Kubernetes and standalone mode, we release Hive on MR3 built with Java 17 only. For Hadoop, we continue to support both Java 8 and Java 17.
Finally we report that Hive on MR3 1.8 beats Trino 418 in terms of total running time on the TPC-DS benchmark with a scale factor of 10TB. With the same hardware used in our previous article, Hive on MR3 1.8 finishes all the queries in 6867 seconds, whereas Trino 418 finishes all the queries in 7424 seconds. Note that Trino returns wrong answers on query 23 and fails to complete query 72.
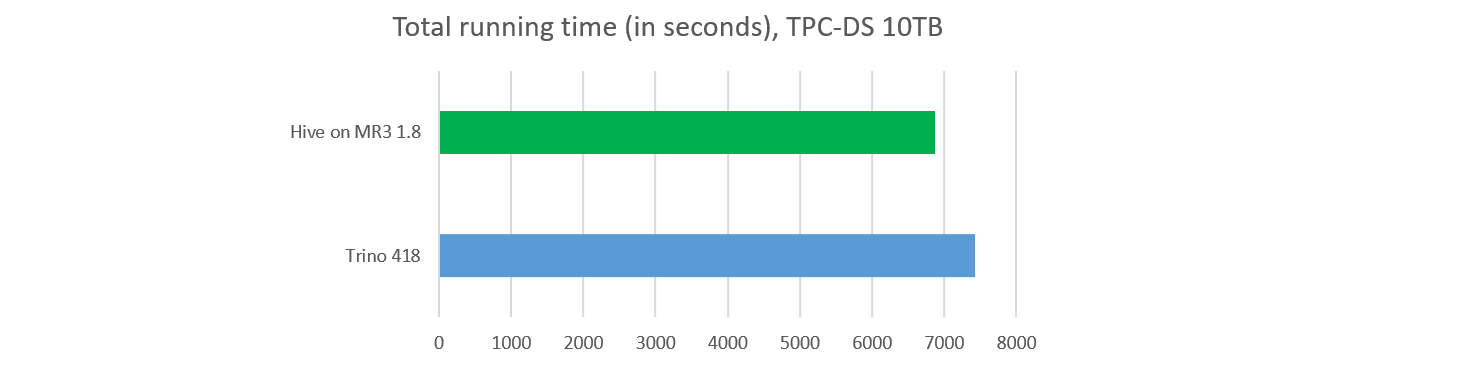
Thus, if Trino is a query engine that runs at ludicrous speed, Hive on MR3 is a data warehouse system that runs at equally ludicrous speed.
If you are interested in Hive on MR3, see Quick Start Guide.