Why you should run Hive on Kubernetes, even in a Hadoop cluster
Jul 19, 2020
Read in 8 minutes
Hive and Presto
Hive and Presto have developed a tortoise-and-hare story over the past 8 years. Initially conceived at Facebook and open sourced in August 2008, Hive was hailed as a breakthrough in the SQL-on-Hadoop technology and generally regarded as the de facto standard. Then in 2012, Facebook started to develop Presto as a replacement of Hive, which was considered too slow for their daily workload. As Facebook was specific about its goal in developing Presto, the future of Hive did not look so bright.
The activity in the Hive community, however, did not dwindle at all. In February 2013, the Hive community, spearheaded by Hortonworks, embarked on the Stinger Initiative with the aim of achieving 100x performance improvement. The outcome of the Stinger Initiative was impressive. The integration of a new execution engine Tez eliminated the most costly overhead in its original execution engine MapReduce, and the introduction of LLAP (Low Latency Analytical Processing) brought the performance to the next level. The in-memory cache implemented in LLAP was also a timely response to the separation of compute and storage.
Eventually Hive has come to outperform Presto by a large margin. The following graph summarizes the result of evaluating Hive 3.1.2 and Presto 317 on the TPC-DS benchmark with a scale factor of 10 terabytes (with details in our previous article). In the experiment, we use Hive on MR3 which is comparable to Hive-LLAP in performance. We observe that with respect to the geometric mean of running times, Hive runs three times faster than Presto: 30.83 seconds for Hive vs 90.07 seconds for Presto. This is no easy feat from a technical perspective, especially because Hive supports fault tolerance whereas Presto does not.
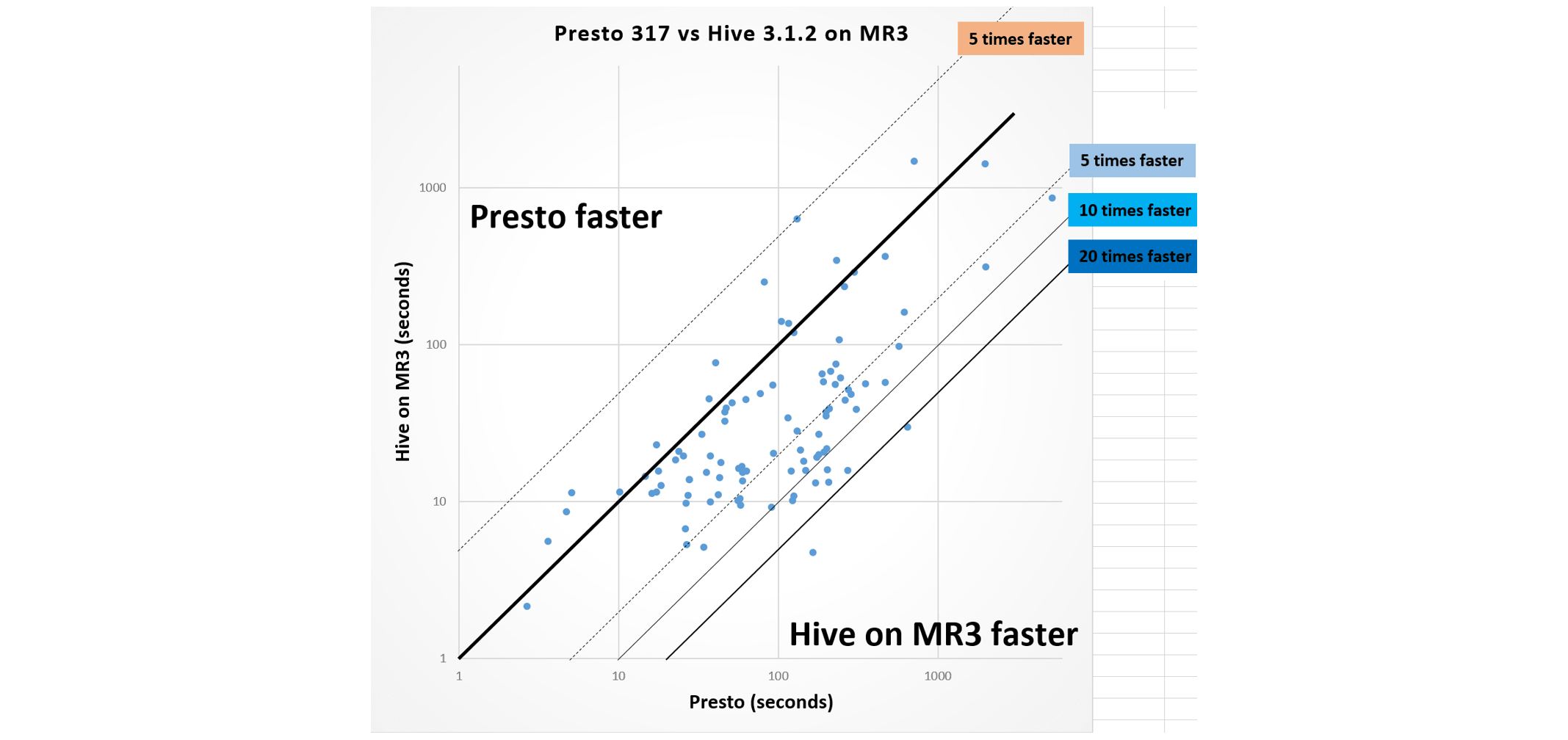
Why choose Presto over Hive?
Nevertheless Presto has its own strengths and is rising rapidly in popularity (as of July 2020). Interestingly its speed is one of its selling points as many industrial users are still under the mistaken impression that Presto is much faster than Hive. For our purpose, we focus on the following core strength of Presto among others – easy installation.
Presto is easy to install. It suffices to copy the binary distribution of Presto in the installation directory on every node, whether in a Hadoop cluster or not. In order to run Presto, the user configures the installation as either a coordinator or a worker and executes a common script on each node. After starting a coordinator, the user can launch workers in any order, which implies that it is also straightforward to add new workers later. The ease and simplicity of the installation process is achievable because Presto has relatively few dependencies.
This strength of Presto, however, really shines in an environment where Docker containers are supported, most notably on Kubernetes. A Docker image can be easily built from the binary distribution of Presto, and after creating a Docker container for a coordinator, the user can create or delete as many Docker containers for workers as necessary. In essence, running Presto with Docker containers is no different from running it directly with the binary distribution.
In stark contrast, installing Hive is a daunting task. First of all, the user should find a Hadoop cluster compatible with Hive to be installed. For example, in order to install Hive 3, the user should either upgrade an existing cluster to Hadoop 3 or create a new Hadoop 3 cluster. Then the user should install a compatible version of Tez. Finally the user should check other dependencies, such as ZooKeeper, in order to use advanced features of Hive such as LLAP. The difficulty and complexity of the installation process is inevitable because Hive has relatively many dependencies, including Hadoop itself.
‘‘Easy installation’’ is a distinctive feature of Presto that is certainly helping to accelerate its adoption, especially in the cloud environment. In comparison, Hive is struggling even in the Hadoop environment. It is not uncommon to see potential users switching to Presto just at the thought of having to upgrade the Hadoop cluster or after failing to configure LLAP properly. Perhaps not by coincidence, Hive is now gradually losing its popularity after its peak in December 2019 (as of July 2020).
Hive on MR3 – a new alternative
Hive on MR3 has been developed with the goal of facilitating the use of Hive, both on Hadoop and on Kubernetes, by exploiting a new execution engine MR3. As such, Hive on MR3 is much easier to install than the original Hive. On Hadoop, it suffices to copy the binary distribution in the installation directory on the master node. On Kubernetes, the user can build a Docker image from the binary distribution (or use a pre-built image) and clone the GitHub repository containing all the scripts.
Hive on MR3 not only retains all the strengths of Hive, but also supports additional features unique to MR3. For example, fault tolerance is more mature than in Tez and Spark, autoscaling is assisted by MR3 itself (rather than relying on an external monitor), and multiple shuffle handlers can run inside a single container so as to eliminate fetch delays. As it is agnostic to the underlying file system, Hive on MR3 fully supports the separation of compute and storage.
Now suppose that a new user wants to try Hive on MR3 in a Hadoop cluster. The reader may well think that it is a no-brainer to choose Hive on MR3 on Hadoop. We, however, recommend Hadoop on MR3 on Kubernetes, even in a Hadoop cluster. Below we explain why.
Hive on MR3 on Kubernetes running in a Hadoop cluster
While it generally runs stable in a typical Hadoop cluster, Hive on MR3 on Hadoop may run into subtle problems due to conflicting configurations. Here are a few examples of such problems:
- Kerberos authentication does not work well because an old version of Java with no support for the unlimited cryptography policy is installed.
- High availability does not work because an incompatible version of ZooKeeper is running.
- The user cannot install Ranger (for managing data security) dedicated to Hive on MR3 because an old version of Ranger is already running.
- It is not easy to run multiple instances of HiveServer2 each with its own security policy.
- On Cloudera CDH, the user should use MR3 based on Hadoop 2.7 in order to run Hive 3.
By running Hive on MR3 on Kubernetes, all such problems either disappear completely or are alleviated considerably. The reason is two-fold: 1) all components now run in a containerized environment and thus the user controls everything; 2) the use of Kubernetes eliminates the need for advanced features specific to Hadoop such as high availability. Moreover Hive on MR3 on Kubernetes is easier to operate than Hive on MR3 on Hadoop. For example, it is easy to run multiple instances of HiveServer2 each with its own security policy while sharing all the resources.
Running Hive on MR3 on Kubernetes in a Hadoop cluster, however, may have two new problems:
- Kubernetes may conflict with Hadoop.
- Hive on MR3 on Kubernetes may run slower than Hive on MR3 on Hadoop.
For the first problem, Kubernetes and Hadoop can coexist in the same cluster because Kubernetes (written in Go) and Hadoop (written in Java) share practically no dependencies. (After installing Kubernetes in a Hadoop cluster, the user can stop Yarn which is no longer needed.) For the second problem, the performance penalty does exist because of the use of Docker containers, but is acceptable with the release of MR3 1.1.
Experiment results
To measure the performance penalty inherent in Kubernetes, we run an experiment with the following settings (where we use both Hive 3 and Hive 4):
- A cluster of 42 nodes each with 24 cores, 96 gigabytes of memory, and 6 HDDs
- 10 gigabit network switch
- HDP 3.1.4 (which is based on Hadoop 3.1.1)
- Kubernetes 1.18
- Hive 3.1.2 and Hive 4.0.0 as of Apr 10, 2020 (after applying HIVE-23114)
- MR3 1.1
- TPC-DS benchmark with a scale factor of 10 terabytes (with modified TPC-DS queries)
For the reader's perusal, we attach the table containing the raw data of the experiment. Here is a link to [Google Docs].
Here is the summary (all measurements in seconds):
| Hive 3 on MR3 | Hive 4 on MR3 | ||||
|---|---|---|---|---|---|
| on Hadoop | on Kubernetes | on Hadoop | on Kubernetes | ||
| Total running time | 12124.30 | 13674.68 | 9480.83 | 11229.45 | |
| Geometric mean | 43.95 | 47.39 | 38.84 | 39.25 |
We make the following observations:
- With respect to the total running time,
- Hive 3 on MR3 on Kubernetes is 12.8 percent slower than on Hadoop.
- Hive 4 on MR3 on Kubernetes is 18.4 percent slower than on Hadoop.
- With respect to the geometric mean of running times,
- Hive 3 on MR3 on Kubernetes is 7.8 percent slower than on Hadoop.
- Hive 4 on MR3 on Kubernetes is 1.0 percent slower than on Hadoop.
We claim that the performance penalty is in an acceptable range and does not outweigh the benefit conferred by Kubernetes. The following graphs show that end users are not very likely to notice the difference in performance.
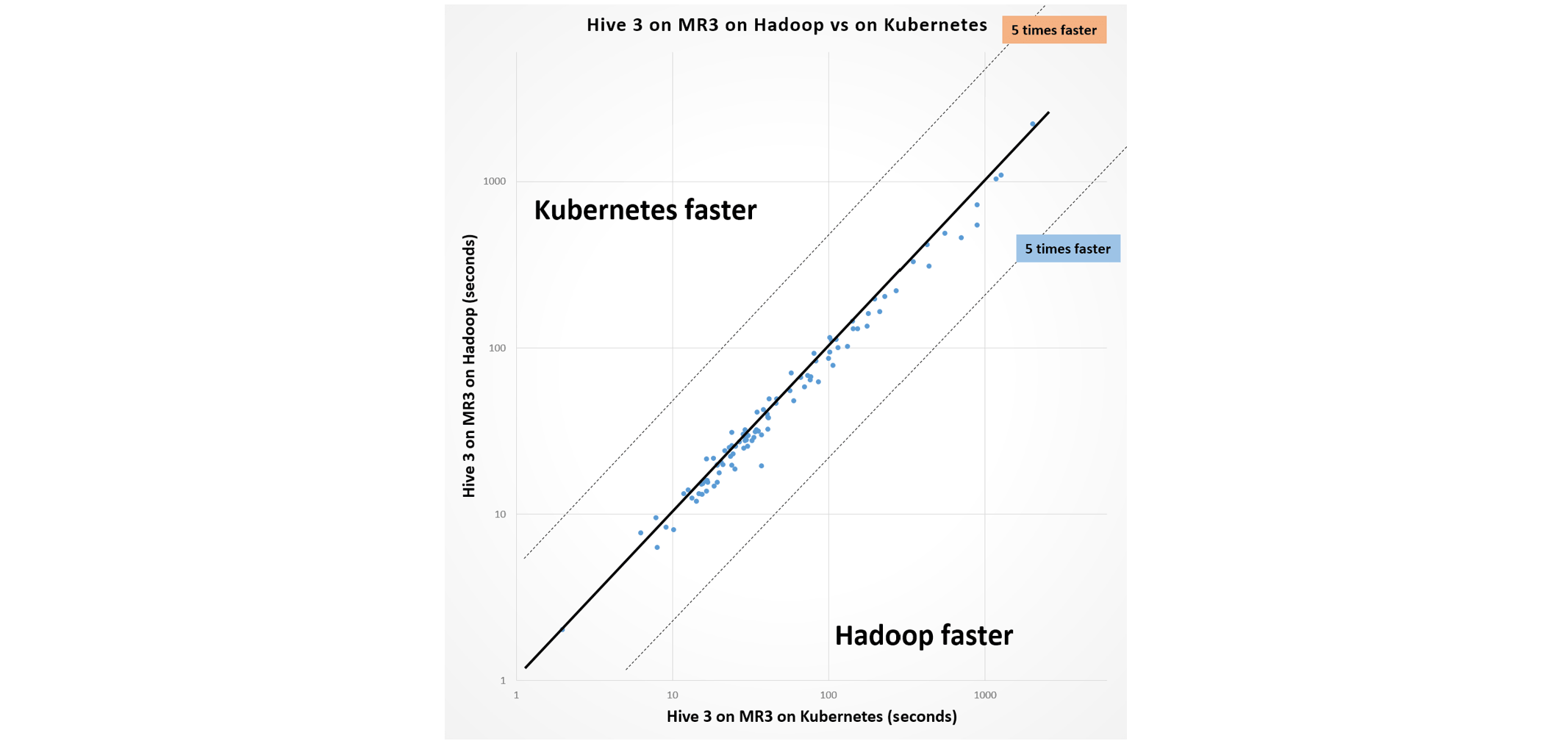
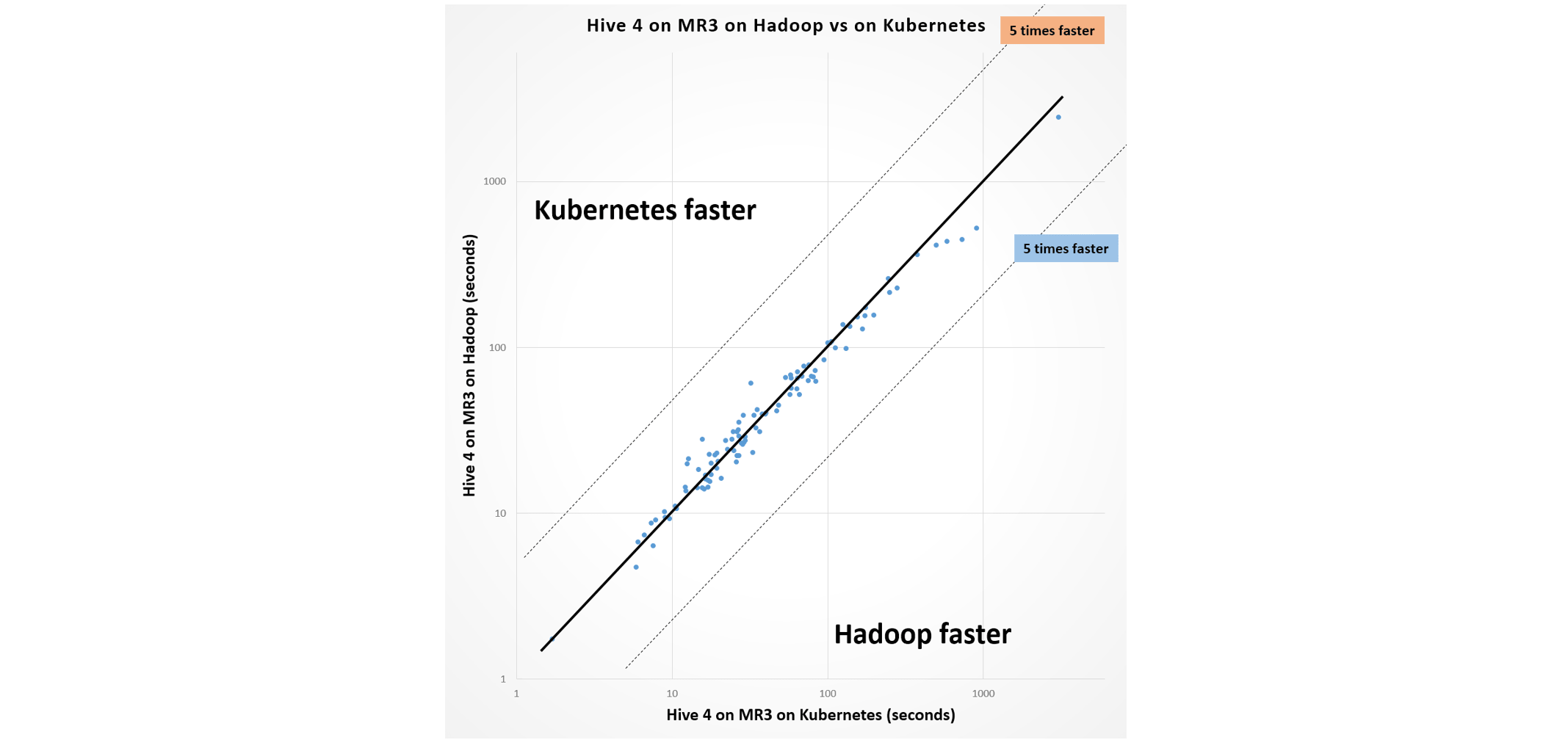
As a side note, we find that Hive 4 runs noticeably faster than Hive 3 on average, and that Hive 3 and Hive 4 differ in the result of query 18 and query 22.
Thus the bottomline is: if you are new to Hive, try Hive on MR3; if you are new to Hive on MR3, try Hive on MR3 on Kubernetes, whether in a Hadoop cluster or not.