Hive vs SparkSQL: Hive-LLAP, Hive on MR3, SparkSQL 2.3.2
Nov 7, 2019
Read in 5 minutes
Introduction
In our previous article published in October 2018, we use the TPC-DS benchmark to compare the performance of Hive-LLAP and SparkSQL 2.3.1 included in HDP 3.0.1 along with Hive 3.1.0 on MR3 0.4. In this article, we update the result by testing SparkSQL 2.3.2 included in HDP 3.1.4. As in the previous experiment, we use the TPC-DS benchmark.
Cluster to use in the experiment
We run the experiment in a 20-node cluster, called Indigo, consisting of 1 master and 19 slaves. All the machines in the Indigo cluster run HDP 3.1.4 and share the following properties:
- 2 x Intel(R) Xeon(R) X5650 CPUs (with hyper-threading enabled)
- 96GB of memory
- 6 x 500GB HDDs
- 10 Gigabit network connection
The memory size for Yarn on a slave node is 84GB. The scale factor for the TPC-DS benchmark is 10TB. We generate the dataset in ORC.
We use a variant of the TPC-DS benchmark introduced in our previous article which replaces an existing LIMIT clause with a new SELECT clause so that different results from the same query translate to different numbers of rows. The reader can find the modified TPC-DS queries in the GitHub repository.
SQL-on-Hadoop systems to compare
We compare the following SQL-on-Hadoop systems.
- Hive-LLAP in HDP 3.1.4
- Hive 3.1.2 running on MR3 0.10
- SparkSQL 2.3.2 included in HDP 3.1.4
We use the default configuration for Hive-LLAP under which each LLAP daemon runs 20 executors of 4GB each.
We use the configuration included in the MR3 release
(hive3/hive-site.xml, mr3/mr3-site.xml, tez/tez-site.xml under conf/tpcds/).
For Hive on MR3, a ContainerWorker uses 40GB of memory, with up to 10 tasks concurrently running in each ContainerWorker.
For SparkSQL, we use the default configuration except for the following:
spark_daemon_memoryset to40960MBspark_thrift_cmd_optsset to--num-executors 18 --executor-memory 72g --executor-cores 20 --conf spark.yarn.am.memory=72g(because we need a host for running AM)spark.dynamicAllocation.initialExecutorsset to 18spark.dynamicAllocation.enabledset to falsespark.scheduler.modeset toFIFO
Note that we do not use Parquet for SparkSQL, so it may not achieve the best performance for the scale factor in use.
Results of sequential tests
In a sequential test, we submit 99 queries from the TPC-DS benchmark. We measure the running time of each query and the number of rows in the result. If the result contains a single row, we compute the sum of all numerical values in it.
For the reader's perusal, we attach the table containing the raw data of the experiment. Here is a link to [Google Docs].
Analysis 1 - Correctness
For every query, the three systems return the same number of rows. The only exception is query 70, for which both Hive 3 on MR3 and SparkSQL reports 124 rows whereas Hive-LLAP reports 25 rows. As Presto also returns 124 rows as shown in our previous article, it is very likely that Hive-LLAP returns a wrong result for query 70.
Analysis 2 - Running time
We summarize running times as follows:
- Hive-LLAP spends 16812 seconds executing all 99 queries.
- Hive 3.1.2 on MR3 0.10 spends 17848 seconds executing all 99 queries.
- SparkSQL fails to finish query 14 and spends 103054 seconds executing the remaining 98 queries. Note that query 72 alone takes 30986 seconds.
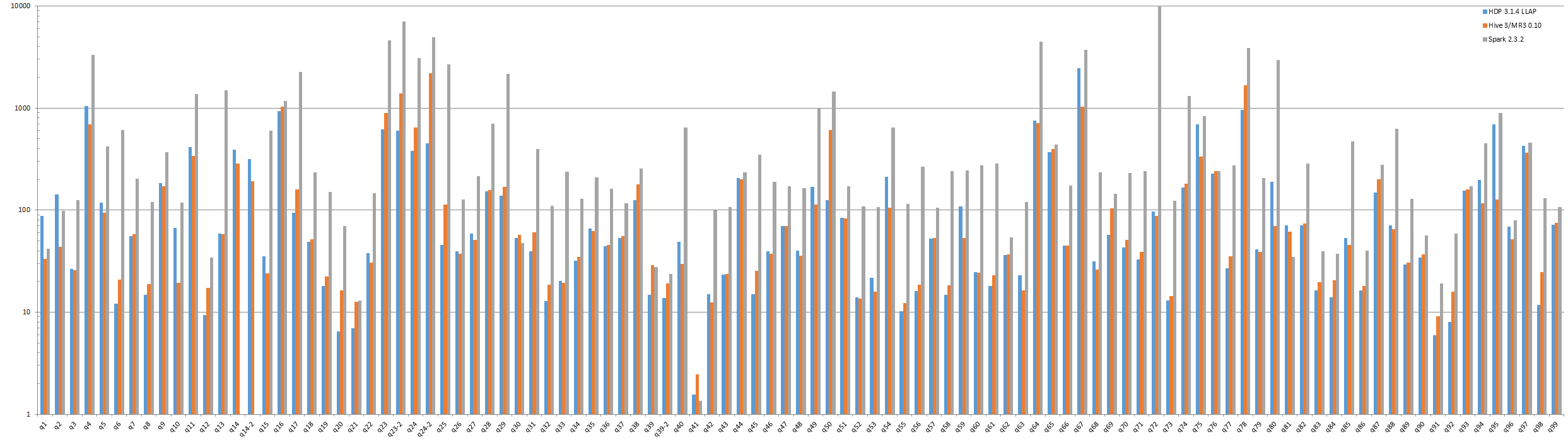
Overall SparkSQL is still much slower than Hive-LLAP and Hive on MR3. If we exclude the result of executing query 72, Hive-LLAP and Hive on MR3 are approximately four times faster on average, which is roughly consistent with the previous result.
Analysis 3. Ranks for individual queries
In order to gain a sense of which system answers queries fast, we rank the three systems according to the running time for each individual query. The system that completes executing a query the fastest is assigned the highest place (1st) for the query under consideration. In this way, we can evaluate the three systems more accurately from the perspective of end users, not of system administrators.
- From left to right, the column corresponds to: Hive-LLAP in HDP 3.1.4, Hive 3.1.2 on MR3 0.10, SparkSQL 2.3.2.
- The first place to the third place is colored in dark green (first), green, light green (third).
![]()
![]()
We observe that Hive-LLAP and Hive on MR3 finish most of the queries faster than SparkSQL. SparkSQL places first only for three queries (query 30, 41, and 81). Overall the user should find Hive-LLAP and Hive on MR3 running much faster than SparkSQL for typical queries.
Conclusion
At the time of writing this article, the latest stable version of SparkSQL is 2.4.4. As we use SparkSQL 2.3.2 in HDP 3.1.4, it may be that our evaluation penalizes SparkSQL to a certain extent. Besides SparkSQL is known to run faster on Parquet datasets than on ORC datasets, so we could further reduce the running time of SparkSQL by generating the dataset in Parquet.
Nevertheless the performance gap between Hive (running either with LLAP or on MR3) and SparkSQL is rather large, and upgrading SparkSQL to 2.4.4 (or even an upcoming release 3.0) is unlikely to turn the tide unless it brings about an order of magnitude performance improvement. Thus we believe that in the foreseeable future, Hive (both Hive-LLAP and Hive on MR3) is likely to run much faster than SparkSQL.