Presto vs Hive on MR3 (Presto 317 vs Hive on MR3 0.10)
Aug 22, 2019
Read in 6 minutes
Introduction
In our previous article, we use the TPC-DS benchmark to compare the performance of three SQL-on-Hadoop systems: Impala 2.12.0+cdh5.15.2+0, Presto 0.217, and Hive 3.1.1 on MR3 0.6. It uses sequential tests to draw the following conclusion:
- Impala runs faster than Hive on MR3 on short-running queries that take less than 10 seconds.
- For long-running queries, Hive on MR3 runs slightly faster than Impala.
- For most queries, Hive on MR3 runs faster than Presto, sometimes an order of magnitude faster.
With the impending release of MR3 0.10, we make a comparison between Presto and Hive on MR3 using both sequential tests and concurrency tests. We use Presto 317, the latest release by the Presto Software Foundation, and Hive 3.1.1 running on MR3 0.10 (snapshot). As in the previous experiment, we use the TPC-DS benchmark.
Cluster to use in the experiment
We run the experiment in the same cluster from the previous article: a 13-node cluster, called Blue, consisting of 1 master and 12 slaves. All the machines in the Blue cluster run Cloudera CDH 5.15.2 and share the following properties:
- 2 x Intel(R) Xeon(R) E5-2640 v4 @ 2.40GHz
- 256GB of memory
- 1 x 300GB HDD, 6 x 1TB SSDs
- 10 Gigabit network connection
In total, the amount of memory of slave nodes is 12 * 256GB = 3072GB. We use HDFS replication factor of 3.
The scale factor for the TPC-DS benchmark is 10TB. For both Presto and Hive on MR3, we generate the dataset in ORC.
We use a variant of the TPC-DS benchmark introduced in the previous article which replaces an existing LIMIT clause with a new SELECT clause so that different results from the same query translate to different numbers of rows. For Presto which uses slightly different SQL syntax, we use another set of queries which are equivalent to the set for Hive on MR3 down to the level of constants. The reader can find the two sets of modified TPC-DS queries in the GitHub repository.
SQL-on-Hadoop systems to compare
We compare the following SQL-on-Hadoop systems.
- Presto 317
- Hive 3.1.1 running on MR3 0.10 (snapshot)
For Presto, we use 194GB for JVM -Xmx and the following configuration (which we have chosen after performance tuning):
query.initial-hash-partitions=12
memory.heap-headroom-per-node=58GB
query.max-total-memory-per-node=120GB
query.max-total-memory=1440GB
query.max-memory-per-node=100GB
query.max-memory=1200GB
sink.max-buffer-size=256MB
task.writer-count=4
node-scheduler.min-candidates=12
node-scheduler.network-topology=flat
optimizer.optimize-metadata-queries=true
join-distribution-type=AUTOMATIC
optimizer.join-reordering-strategy=AUTOMATIC
task.concurrency=16
For Hive on MR3, we allocate 90% of the cluster resource to Yarn.
We use the configuration included in the MR3 release (hive3/hive-site.xml, mr3/mr3-site.xml, tez/tez-site.xml under conf/tpcds/).
A ContainerWorker uses 36GB of memory, with up to three tasks concurrently running in each ContainerWorker.
Results of sequential tests
In a sequential test, we submit 99 queries from the TPC-DS benchmark. If a query fails, we measure the time to failure and move on to the next query. We measure the running time of each query and the number of rows in the result. If the result contains a single row, we compute the sum of all numerical values in it. We have manually verified that Hive on MR3 and Presto agree on the result for every query that returns a single row.
For the reader's perusal, we attach the table containing the raw data of the experiment. Here is a link to [Google Docs].
We summarize the result of running Presto and Hive on MR3 as follows:
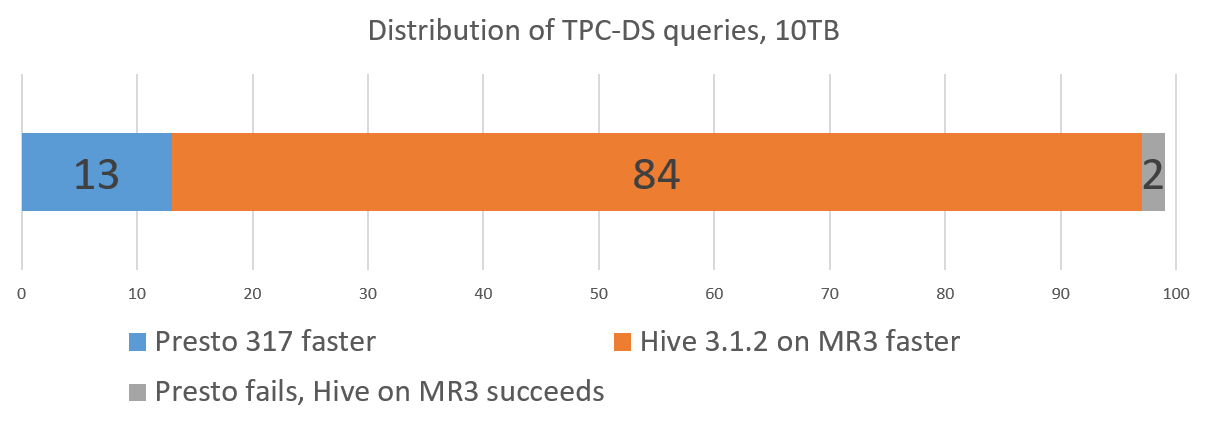
- Presto successfully finishes 97 queries, but fails to finish 2 queries.
- Hive on MR3 successfully finishes all 99 queries.
- Presto takes 22899 seconds to execute all 99 queries.
- Hive on MR3 takes 11033 seconds to execute all 99 queries.
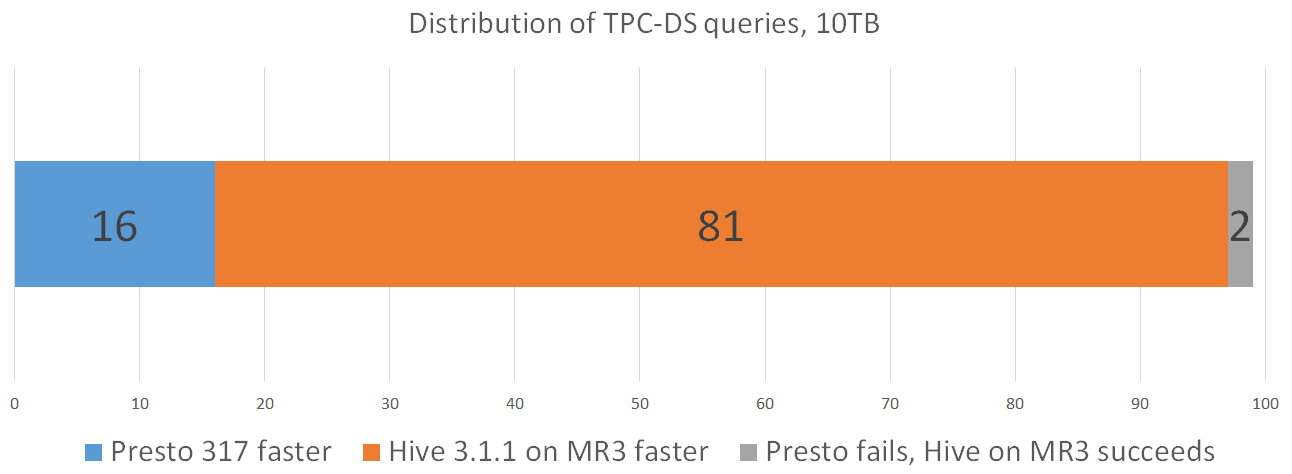
For the set of 97 queries that both Presto and Hive on MR3 successfully finish:
- Presto takes 22537 seconds, and Hive on MR3 takes 9777 seconds.
- Presto runs faster than Hive on MR3 on 16 queries.
- Hive on MR3 runs faster than Presto on 81 queries.
For most queries, the two systems return the same result and are thus sound with an extremely high probability. For query 21, Hive on MR3 reports about 10 percent fewer rows than Presto (which is the same result reported in the previous article). For query 68, the two systems report completely different results: Hive on MR3 returns no rows while Presto returns 21137346 rows. Hence at least one of Presto and Hive on MR3 is unsound with respect to query 68.
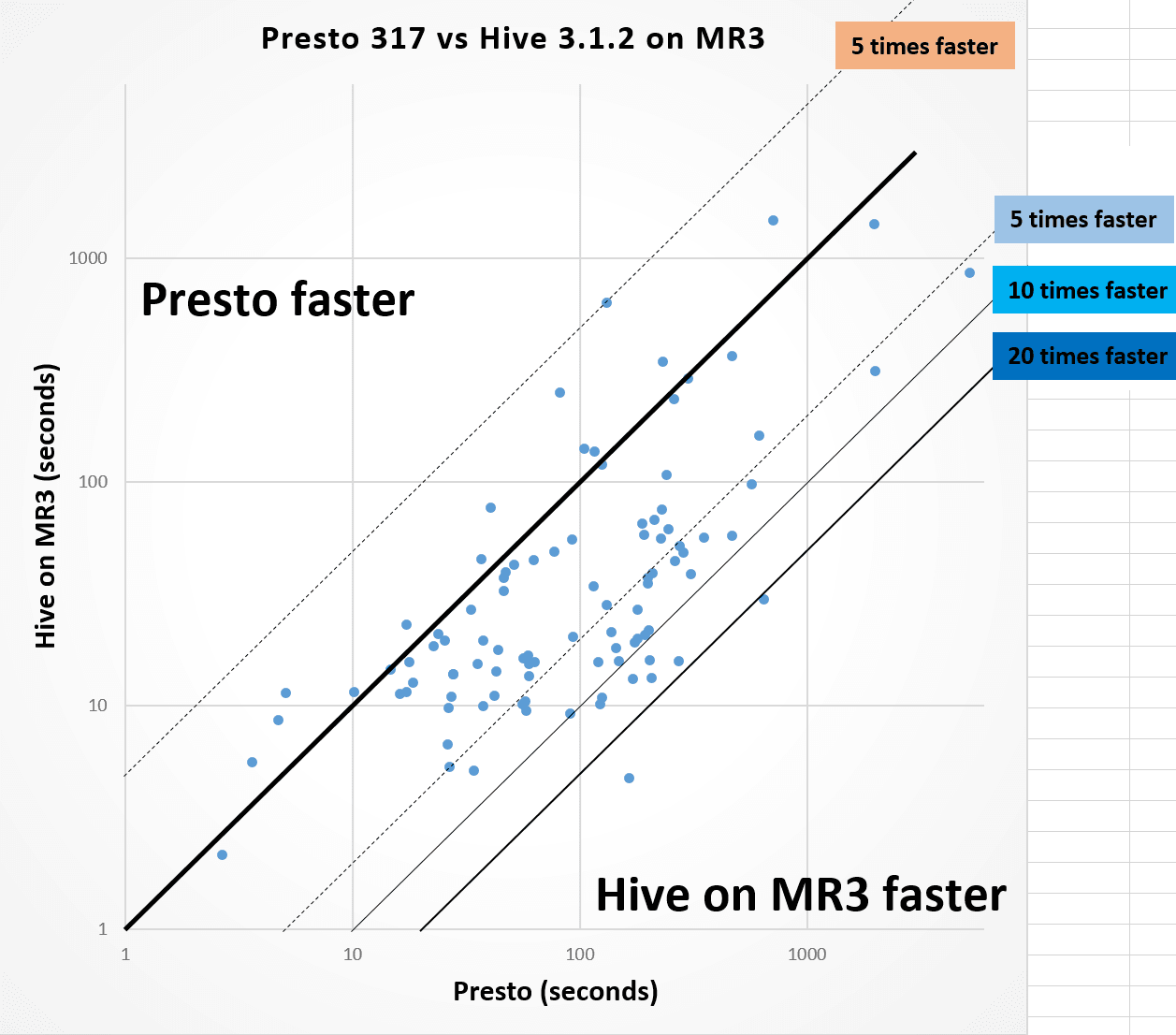
The following graph shows the distribution of 97 queries that both Presto and Hive on MR3 successfully finish. Each dot corresponds to a query, and its x-coordinate represents the running time of Presto (in logarithmic scale) whereas its y-coordinate represents the running time of Hive on MR3. The relatively long distance from many dots to the diagonal line indicates that Hive on MR3 runs much faster than Presto on their corresponding queries. We see that Hive on MR3 runs more than 5 times faster for 22 queries, more than 10 times faster for 5 queries, and more than 20 times faster for 2 queries than Presto.
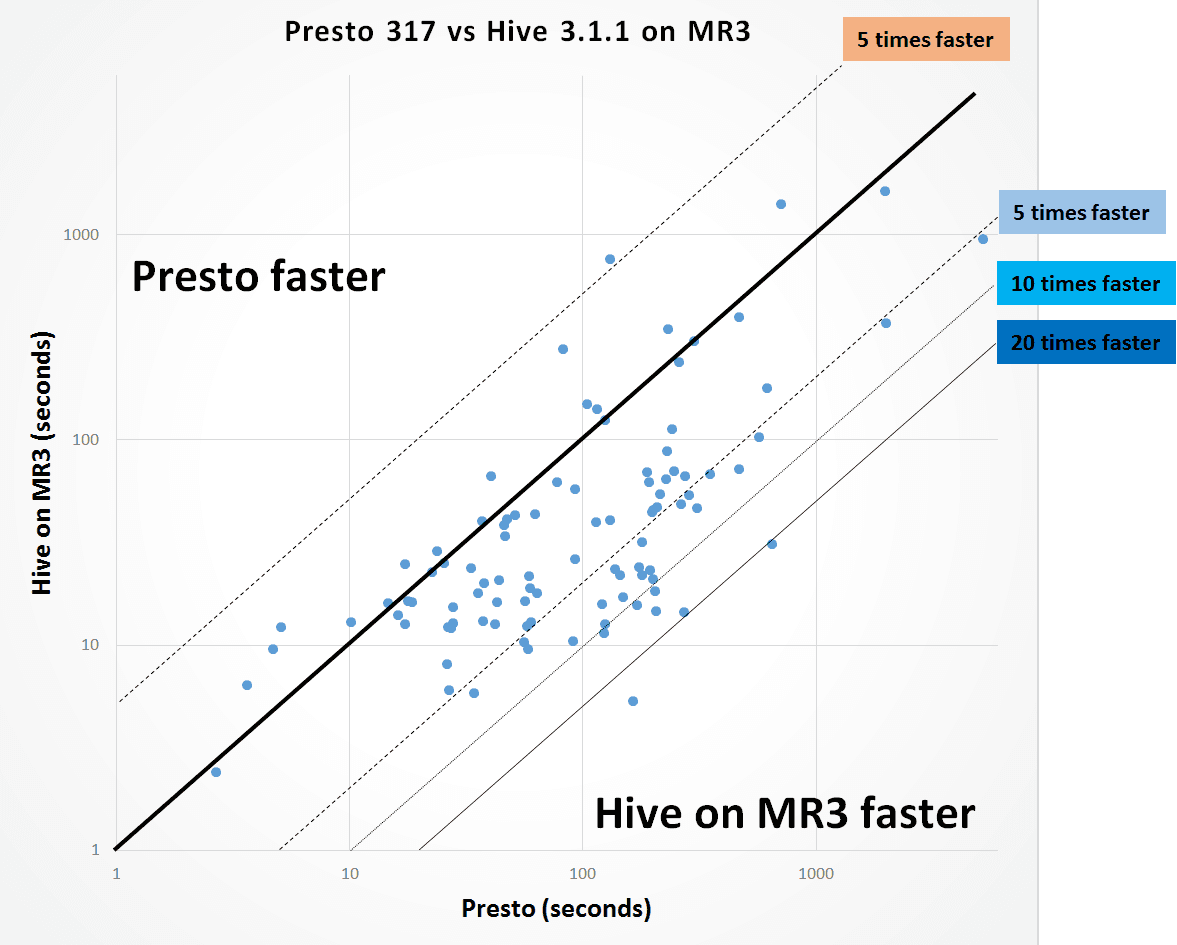
From the experiment, we conclude as follows:
- For most queries, Hive on MR3 runs faster than Presto, sometimes an order of magnitude faster.
Results of concurrency tests
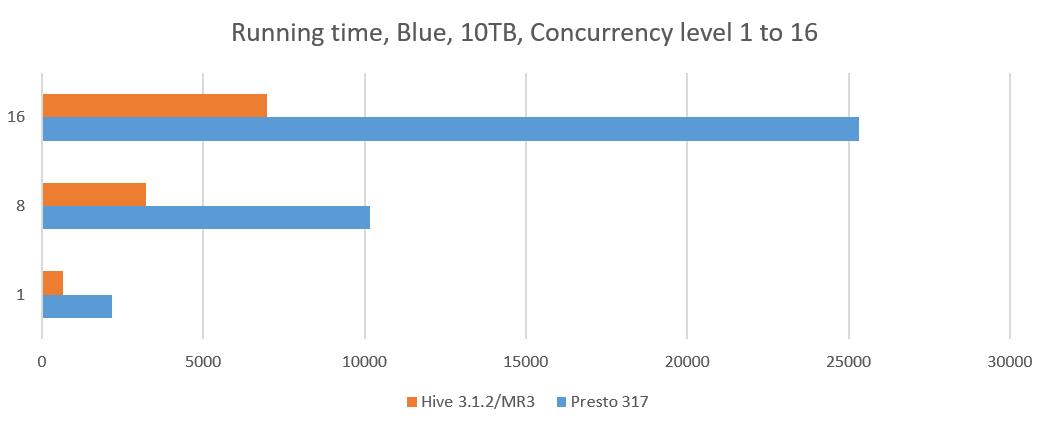
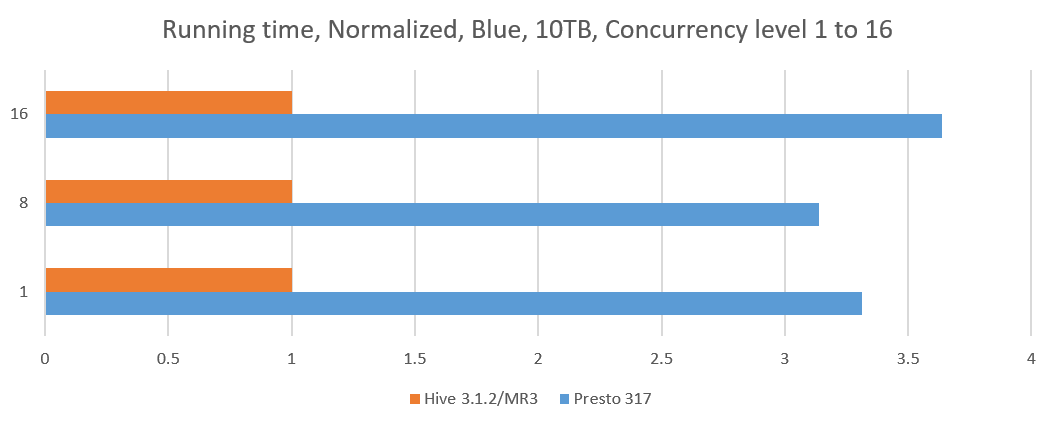
In our experiment, we choose a concurrency level from 8 to 16 and start as many Beeline or Presto clients (from 8 clients up to 16 clients), each of which submits 17 queries, query 25 to query 40, from the TPC-DS benchmark. In order to better simulate a realistic environment, each Beeline or Presto client submits these 17 queries in a unique sequence. For each run, we measure the longest running time of all the clients. Since the cluster remains busy until the last client completes the execution of all its queries, the longest running time can be thought of as the cost of executing queries for all the clients.
The following table shows the results of concurrency tests. The results for a concurrency level of 1 are obtained from the previous sequential tests. For Presto, we collect results from 5 separate runs and choose the median. For Hive on MR3, we collect the result from a single run for each concurrency level because the total execution time is highly stable.

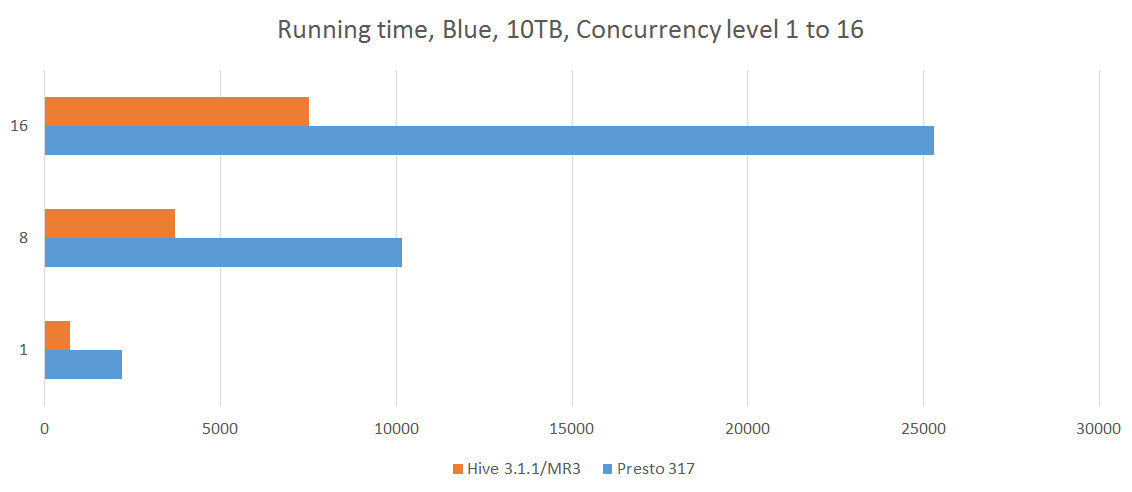
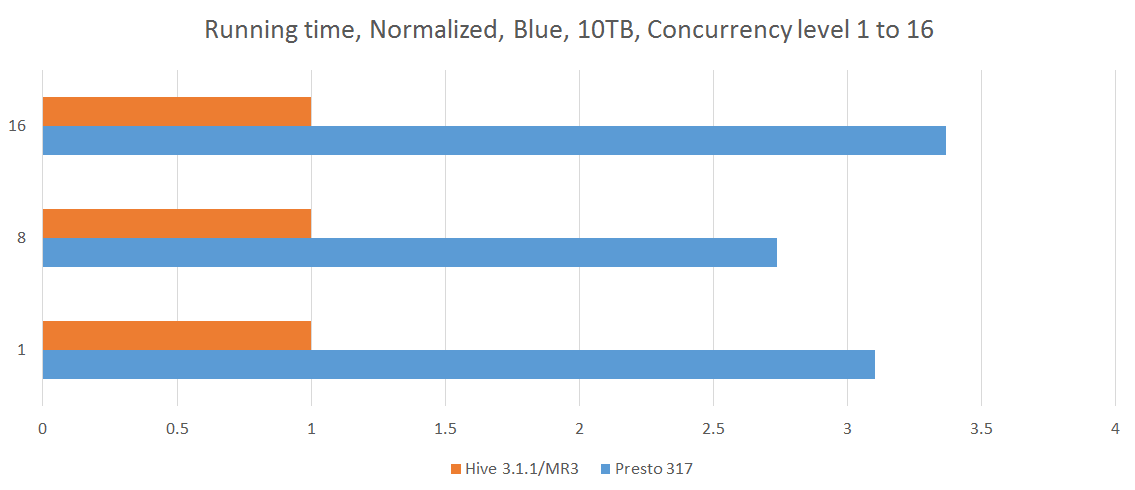
From the experiment, we conclude as follows:
- For concurrent queries, Hive on MR3 achieves a significant reduction in the running time with respect to Presto, nearly tripling the throughput.
Conclusion
In comparison with Presto 0.217 as reported in the previous article, Presto 317 successfully finishes two more queries (query 72 and query 80) in the TPC-DS benchmark while reducing the total execution time by about 7 percent (from 24467 seconds to 22899 seconds). The gap in performance between Presto and Hive on MR3, however, stays the same because in comparison with Hive 3.1.1 on MR3 0.6, Hive 3.1.1 on MR3 0.10 (snapshot) also achieves a similar level of improvement by reducing the total execution time by about 10 percent (from 12249 seconds to 11033 seconds). Thus, at least in the foreseeable future, Hive on MR3 is likely to run much faster than Presto.
[Update: October 26, 2019]
Here is the result of testing Hive 3.1.2 on MR3 0.10 (using the final release). Hive on MR3 takes 10172 seconds to execute all 99 queries (a reduction of 8 percent from 11033 seconds).