Performance Evaluation of Impala, Presto, and Hive on MR3
Mar 22, 2019
Read in 8 minutes
Introduction
In our previous article, we use the TPC-DS benchmark to compare the performance of five SQL-on-Hadoop systems: Hive-LLAP, Presto, SparkSQL, Hive on Tez, and Hive on MR3. As it uses both sequential tests and concurrency tests across three separate clusters, we believe that the performance evaluation is thorough and comprehensive enough to closely reflect the current state in the SQL-on-Hadoop landscape. Our key findings are:
- Overall those systems based on Hive are much faster and more stable than Presto and SparkSQL. In particular, SparkSQL, which is still widely believed to be much faster than Hive (especially in academia), turns out to be way behind in the race.
- Hive on MR3 is as fast as Hive-LLAP in sequential tests.
- Hive on MR3 exhibits the best performance in concurrency tests in terms of concurrency factor.
The previous performance evaluation, however, is incomplete in that it is missing a key player in the SQL-on-Hadoop landscape – Impala.
With the release of MR3 0.6, we use the TPC-DS benchmark to make a head-to-head comparison between Impala and Hive on MR3 in the main playground for Impala, namely Cloudera CDH. As Impala achieves its best performance only when plenty of memory is available on every node, we set up a new cluster in which each node has 256GB of memory (twice larger than the minimum recommended memory). In addition, we include the latest version of Presto in the comparison.
Cluster to use in the experiment
We run the experiment in a 13-node cluster, called Blue, consisting of 1 master and 12 slaves. All the machines in the Blue cluster run Cloudera CDH 5.15.2 and share the following properties:
- 2 x Intel(R) Xeon(R) E5-2640 v4 @ 2.40GHz
- 256GB of memory
- 1 x 300GB HDD, 6 x 1TB SSDs
- 10 Gigabit network connection
In total, the amount of memory of slave nodes is 12 * 256GB = 3072GB. We use HDFS replication factor of 3.
The scale factor for the TPC-DS benchmark is 10TB. For Impala, we generate the dataset in Parquet. For Presto and Hive on MR3, we generate the dataset in ORC.
Instead of using TPC-DS queries tailored to individual systems, we use the same set of unmodified TPC-DS queries. For Presto which uses slightly different SQL syntax, we use another set of queries which are equivalent to the set for Impala and Hive on MR3 down to the level of constants.
SQL-on-Hadoop systems to compare
We compare the following SQL-on-Hadoop systems.
- Impala 2.12.0+cdh5.15.2+0 in Cloudera CDH 5.15.2
- Presto 0.217
- Hive 3.1.1 on MR3 0.6
For Impala, we use the default configuration set by CDH, and allocate 90% of the cluster resource.
For Presto, we use 194GB for JVM -Xmx and the following configuration (which we have chosen after performance tuning):
query.initial-hash-partitions=12
memory.heap-headroom-per-node=58GB
query.max-total-memory-per-node=120GB
query.max-total-memory=1440GB
query.max-memory-per-node=100GB
query.max-memory=1200GB
sink.max-buffer-size=256MB
task.writer-count=4
node-scheduler.min-candidates=12
node-scheduler.network-topology=flat
optimizer.optimize-metadata-queries=true
join-distribution-type=AUTOMATIC
optimizer.join-reordering-strategy=AUTOMATIC
For Hive on MR3, we allocate 90% of the cluster resource to Yarn.
We use the configuration included in the MR3 release 0.6 (hive5/hive-site.xml, mr3/mr3-site.xml, tez/tez-site.xml under conf/tpcds/).
A ContainerWorker uses 36GB of memory, with up to three tasks concurrently running in each ContainerWorker.
Results of sequential tests
In a sequential test, we submit 99 queries from the TPC-DS benchmark. If a query fails, we measure the time to failure and move on to the next query. We measure the running time of each query, and also count the number of queries that successfully return answers.
For the reader's perusal, we attach the table containing the raw data of the experiment. A running time of 0 seconds means that the query does not compile (which occurs only in Impala). A negative running time, e.g., -639.367, means that the query fails in 639.367 seconds. Here is a link to [Google Docs].
Result 1. Impala vs Hive on MR3
We summarize the result of running Impala and Hive on MR3 as follows:
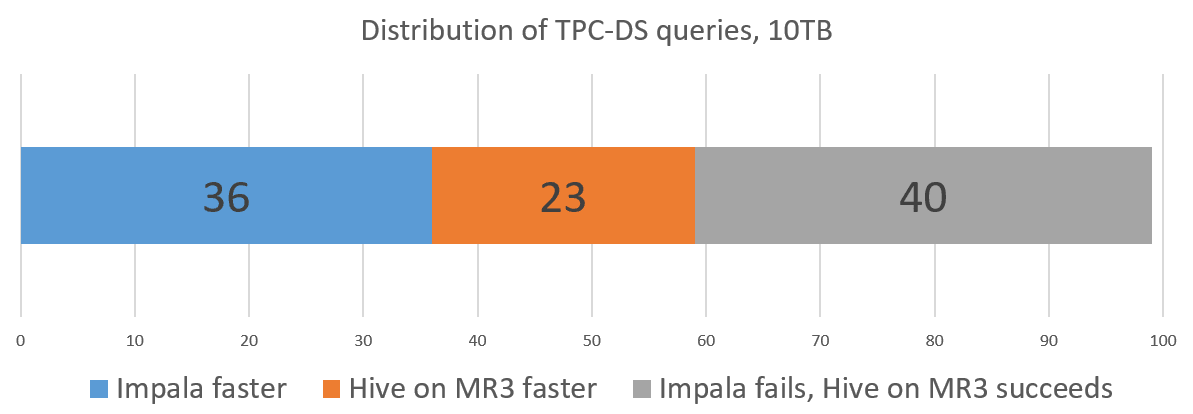
- Impala successfully finishes 59 queries, but fails to compile 40 queries.
- Hive on MR3 successfully finishes all 99 queries.
- Impala takes 7026 seconds to execute 59 queries.
- Hive on MR3 takes 12249 seconds to execute all 99 queries.
For the set of 59 queries that both Impala and Hive on MR3 successfully finish:
- Impala takes 7026 seconds, and Hive on MR3 takes 6247 seconds.
- Impala runs faster than Hive on MR3 on 36 queries.
- Hive on MR3 runs faster than Impala on 23 queries.
The following graph shows the distribution of 59 queries that both Impala and Hive on MR3 successfully finish. Each dot corresponds to a query, and its x-coordinate represents the running time of Impala whereas its y-coordinate represents the running time of Hive on MR3. Thus all the dots above the diagonal line correspond to those queries that Impala finishes faster than Hive on MR3, and all the dots below the diagonal line correspond to those queries that Hive on MR3 finishes faster than Impala.
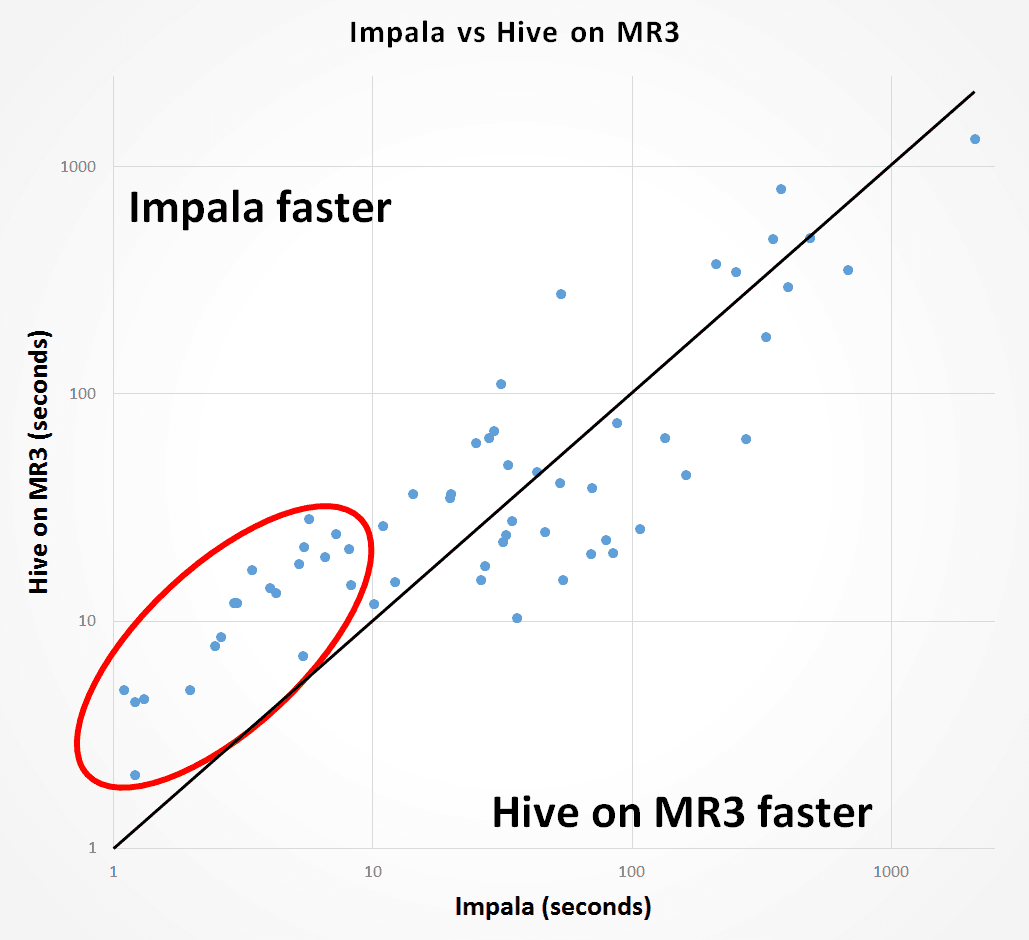
We observe that Impala runs consistently faster than Hive on MR3 for those 20 queries that take less than 10 seconds (shown inside the red circle). For such queries, however, the user experience for Hive on MR3 should not change drastically in practice because Hive on MR3 spends less than 30 seconds even in the worst case. For the remaining 39 queries that take longer than 10 seconds, Hive on MR3 runs about 15 percent faster than Impala on average (6944.55 seconds for Impala and 5990.754 seconds for Hive on MR3).
From the experiment, we conclude as follows:
- Impala runs faster than Hive on MR3 on short-running queries that take less than 10 seconds.
- For long-running queries, Hive on MR3 runs slightly faster than Impala.
- On the whole, Hive on MR3 is more mature than Impala in that it can handle a more diverse range of queries.
Result 2. Presto vs Hive on MR3
We summarize the result of running Presto and Hive on MR3 as follows:
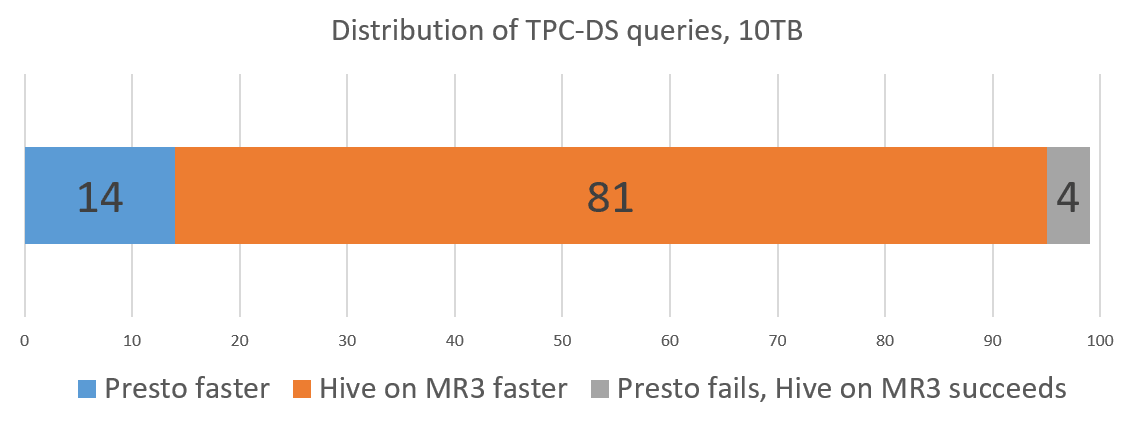
- Presto successfully finishes 95 queries, but fails to finish 4 queries.
- Hive on MR3 successfully finishes all 99 queries.
- Presto takes 24467 seconds to execute all 99 queries.
- Hive on MR3 takes 12249 seconds to execute all 99 queries.
For the set of 95 queries that both Presto and Hive on MR3 successfully finish:
- Presto takes 23707 seconds, and Hive on MR3 takes 10489 seconds.
- Presto runs faster than Hive on MR3 on 14 queries.
- Hive on MR3 runs faster than Presto on 81 queries.
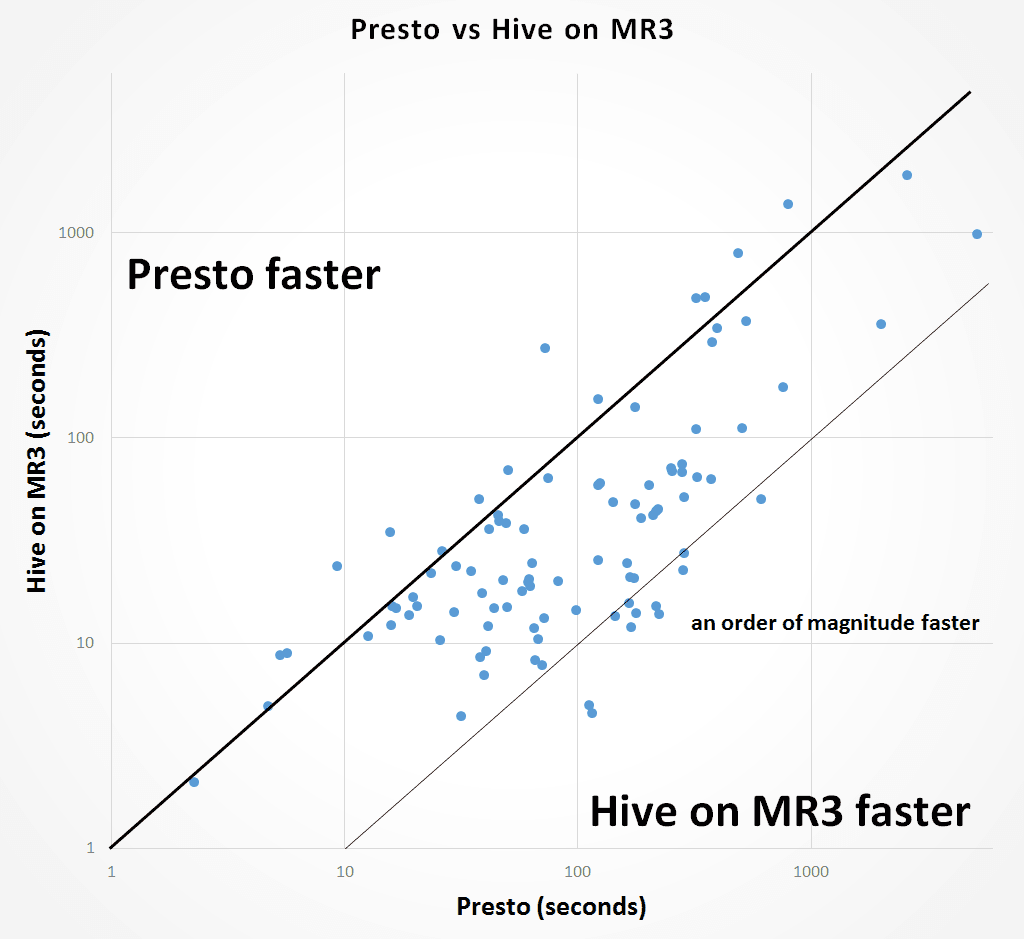
Similarly to the graph shown above, the following graph shows the distribution of 95 queries that both Presto and Hive on MR3 successfully finish. The relatively long distance from many dots to the diagonal line indicates that Hive on MR3 runs much faster than Presto on their corresponding queries. We see that for 11 queries, Hive on MR3 runs an order of magnitude faster than Presto.
For the experiment, we conclude as follows:
- For most queries, Hive on MR3 runs faster than Presto, sometimes an order of magnitude faster.
- On the whole, Hive on MR3 and Presto are comparable to each other in their maturity.
Conclusion
Impala was first announced by Cloudera as a SQL-on-Hadoop system in October 2012, and Presto was conceived at Facebook as a replacement of Hive in 2012. At the time of their inception, Hive was generally regarded as the de facto standard for running SQL queries on Hadoop, but was also notorious for its sluggish speed which was due to the use of MapReduce as its execution engine. Just a few years later, it appeared like Impala and Presto literally took over the Hive world (at least with respect to speed). SparkSQL was also quick to jump on the bandwagon by virtue of its so-called in-memory processing which stood in stark contrast to disk-based processing of MapReduce.
Fast forward to 2019, and we see that Hive is now the strongest player in the SQL-on-Hadoop landscape in all aspects – speed, stability, maturity – while it continues to be regarded as the de facto standard for running SQL queries on Hadoop. Moreover its Metastore has evolved to the point of being almost indispensable to every SQL-on-Hadoop system. After all, there should be a good reason why Hive stands much higher than Impala, Presto, and SparkSQL in the popular database ranking.
Because of the dizzying speed of technological change, from Big Data to Cloud Computing, it is hard to predict the future of Hive accurately. (Who would have thought back in 2012 that the year 2019 would see Hive running much faster than Presto, which was invented for the very purpose of overcoming the slow speed of Hive by the very company that invented Hive?) We see, however, an irresistible trend that Hive cannot ignore in the upcoming years: gravitation toward containers and Kubernetes in cloud computing. In fact, Hive-LLAP running on Kubernetes is apparently already under development at Hortonworks (now part of Cloudera). In the case of Hive on MR3, it already runs on Kubernetes. We believe that Hive on MR3 lends itself much better to Kubernetes than Hive-LLAP because its architectural principle is to utilize ephemeral containers whereas the execution of Hive-LLAP revolves around persistent daemons. From the next release of MR3, we will focus on incorporating new features particularly useful for Kubernetes and cloud computing.