Performance Evaluation of SQL-on-Hadoop Systems using the TPC-DS Benchmark
Oct 30, 2018
Read in 16 minutes
NOTE: We have published a follow-up article in which we evaluate Impala: Performance Evaluation of Impala, Presto, and Hive on MR3.
Introduction
We often ask questions on the performance of SQL-on-Hadoop systems:
- How fast is Hive-LLAP in comparison with Presto, SparkSQL, or Hive on Tez?
- As it is an MPP-style system, does Presto run the fastest if it successfully executes a query?
- As it stores intermediate data in memory, does SparkSQL run much faster than Hive on Tez in general?
- What is the best system for running concurrent queries?
- …
While interesting in their own right, these questions are particularly relevant to industrial practitioners who want to adopt the most appropriate technology to meet their need.
There are a plethora of benchmark results available on the internet, but we still need new benchmark results. Since all SQL-on-Hadoop systems constantly evolve, the landscape gradually changes and previous benchmark results may already be obsolete. Moreover the hardware employed in a benchmark may favor certain systems only, and a system may not be configured at all to achieve the best performance. On the other hand, the TPC-DS benchmark continues to remain as the de facto standard for measuring the performance of SQL-on-Hadoop systems.
With the release of MR3 0.4, we report our experimental results to answer some of those questions regarding SQL-on-Hadoop systems. The results are by no means definitive, but should shed light on where each system lies and in which direction it is moving in the dynamic landscape of SQL-on-Hadoop. In particular, the results may contradict some common beliefs on Hive, Presto, and SparkSQL.
Clusters to use in the experiment
We run the experiment in three different clusters: Red, Gold, and Indigo. All the machines in the clusters run HDP (HortonWorks Data Platform) and share the following properties:
- 2 x Intel(R) Xeon(R) X5650 CPUs
- 192GB of memory on Red, 96GB of memory on Gold and Indigo
- 6 x 500GB HDDs
- 10 Gigabit network connection
| Red | Gold | Indigo | |
|---|---|---|---|
| Hadoop version | Hadoop 2.7.3 (HDP 2.6.4) | Hadoop 2.7.3 (HDP 2.6.4) | Hadoop 3.1.0 (HDP 3.0.1) |
| Number of master nodes | 1 | 2 | 2 |
| Number of slave nodes | 10 | 40 | 19 |
| Scale factor for the TPC-DS benchmark | 1TB | 10TB | 3TB |
| Memory size for Yarn on a slave node | 168GB | 84GB | 84GB |
| Security | Kerberos | No | No |
In total, the amount of memory of slaves nodes is:
- 10 * 196GB = 1960GB on the Red cluster
- 40 * 96GB = 3840GB on the Gold cluster
- 19 * 96GB = 1824GB on the Indigo cluster
We use HDFS replication factor of 3 on Hadoop 2.7.3.
SQL-on-Hadoop systems to compare
We compare the following SQL-on-Hadoop systems. Note that Hive 3.1.0 is officially supported only on Hadoop 3, so we have modified the source code so as to run it on Hadoop 2.7.3 as well.
On the Red and Gold clusters (which run HDP 2.6.4 based on Hadoop 2.7.3):
- Hive-LLAP included in HDP 2.6.4
- Presto 0.203e (with cost-based optimization enabled)
- SparkSQL 2.2.0 included in HDP 2.6.4
- Hive 3.1.0 running on top of Tez
- Hive 3.1.0 running on top of MR3 0.4
- Hive 2.3.3 running on top of MR3 0.4
On the Indigo cluster (which runs HDP 3.0.1 based on Hadoop 3.1.0):
- Hive-LLAP included in HDP 3.0.1
- Presto 0.208e (with cost-based optimization enabled)
- SparkSQL 2.3.1 included in HDP 3.0.1
- Hive on Tez included in HDP 3.0.1
- Hive 3.1.0 running on top of MR3 0.4
- Hive 2.3.3 running on top of MR3 0.4
For Hive-LLAP, we use the default configuration set by Ambari. An LLAP daemon uses 160GB on the Red cluster and 76GB on the Gold and Indigo clusters. An ApplicationMaster uses 4GB on all the clusters.
For Presto, we use the following configuration (which we have chosen after performance tuning):
# for the Red cluster
query.initial-hash-partitions 10
query.max-memory-per-node 120GB
query.max-total-memory-per-node 120GB
memory.heap-headroom-per-node 16GB
resources.reserved-system-memory 24GB
sink.max-buffer-size 20GB
node-scheduler.min-candidates 10
# for the Gold and Indigo clusters
query.initial-hash-partitions 40
query.max-memory-per-node 60GB
query.max-total-memory-per-node 60GB
memory.heap-headroom-per-node 8GB
resources.reserved-system-memory 12GB
sink.max-buffer-size 10GB
node-scheduler.min-candidates 40
# for all clusters
task.writer-count 4
node-scheduler.network-topology flat
optimizer.optimize-metadata-queries TRUE
join-distribution-type AUTOMATIC
optimizer.join-reordering-strategy COST_BASED/AUTOMATIC
A Presto worker uses 144GB on the Red cluster and 72GB on the Gold and Indigo clusters (for JVM -Xmx).
For SparkSQL,
we use the default configuration set by Ambari, with spark.sql.cbo.enabled and spark.sql.cbo.joinReorder.enabled set to true in addition.
Spark Thrift Server uses the following option:
--num-executors 19 --executor-memory 74g --conf spark.yarn.am.memory=74gon Red--num-executors 39 --executor-memory 72g --conf spark.yarn.am.memory=72gon Gold--num-executors 18 --executor-memory 72g --conf spark.yarn.am.memory=72gon Indigo
For Hive 3.1.0 and 2.3.3, we use the configuration included in the MR3 release 0.4 (hive2/hive-site.xml, hive5/hive-site.xml, mr3/mr3-site.xml, tez3/tez-site.xml under conf/tpcds/).
For Hive on Tez, a container uses 16GB on the Red cluster, 10GB on the Gold cluster, and 8GB on the Indigo cluster.
For Hive on MR3, a container uses:
- 16GB on the Red cluster, with a single Task running in each ContainerWorker
- 20GB on the Gold cluster, with up to two Tasks running in each ContainerWorker
- 40GB on the Indigo cluster, with up to five Tasks running in each ContainerWorkers
Part I. Results of sequential tests
In a sequential test, we submit 99 queries from the TPC-DS benchmark with a Beeline or Presto client. For the Red and Gold clusters, we report the result of running 103 queries because query 14, 23, 24, and 39 proceed in two stages. For the Indigo cluster, we report the result of running 99 queries because Presto 0.208e does not split these four queries and thus execute a total of 99 queries. If a query fails, we measure the time to failure and move on to the next query. We set a timeout of 3600 seconds for each query on the Red and Indigo clusters (but not on the Gold cluster).
For the reader's perusal, we attach three tables containing the raw data of the experiment. A running time of 0 seconds means that the query does not compile, and a negative running time, e.g., -639.367, means that the query fails in 639.367 seconds. Here is a link to [Google Docs].
Analysis 1. Number of completed queries
We count the number of queries that successfully return answers:
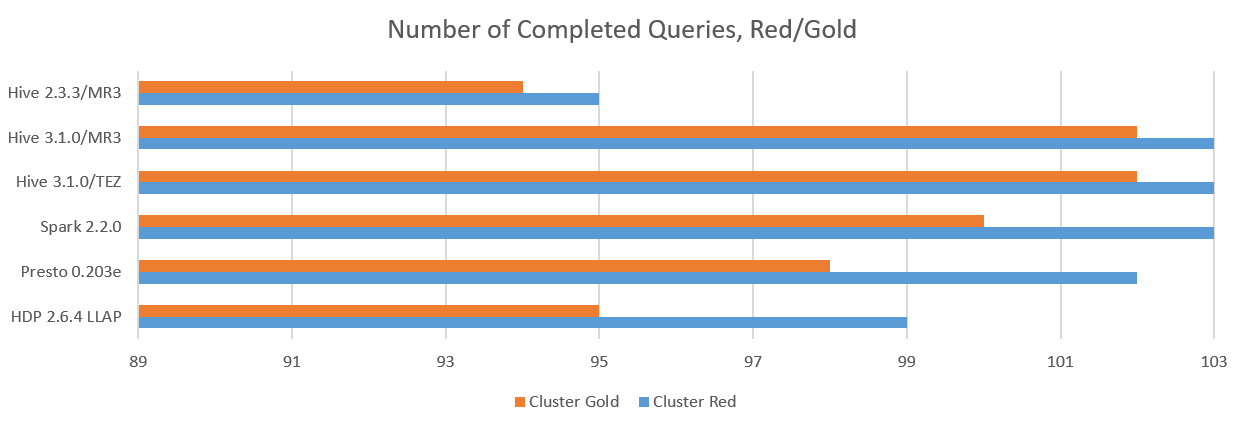
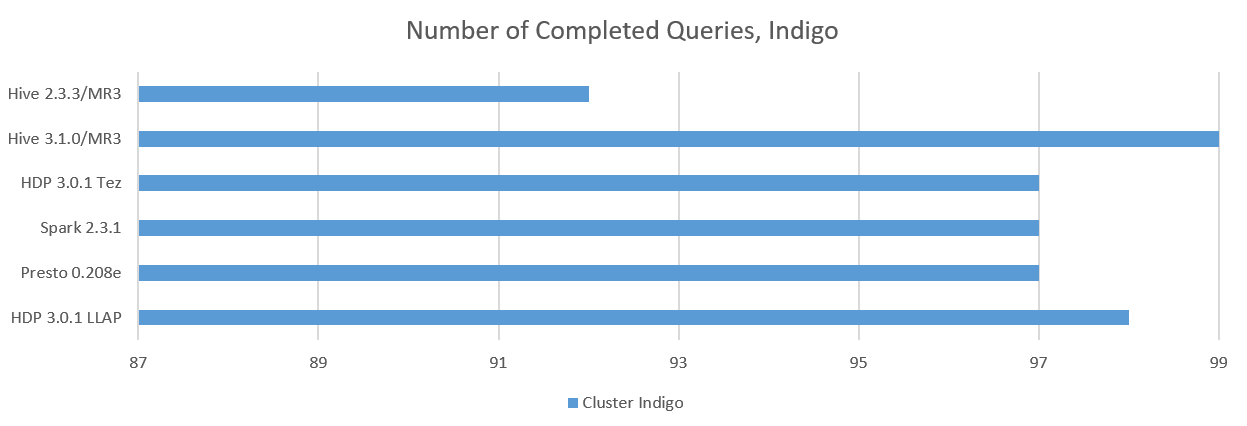
Here is the summary:
- On the Red cluster, Hive 3.1.0 on MR3, Hive 3.1.0 on Tez, and SparkSQL 2.2.0 complete executing all 103 queries.
- On the Gold cluster, Hive 3.1.0 on MR3 and Hive 3.1.0 on Tez fail only on query 16 and complete executing the most number of queries.
- On the Indigo cluster, Hive 3.1.0 on MR3 is the only system that completes executing all 99 queries. Hive-LLAP of HDP 3.0.1 fails on query 78 as it gets stuck after the compilation step.
Analysis 2. Total running time
We measure the total running time of all queries, whether successful or not:


Unfortunately it is hard to make a fair comparison from this result because not all the systems are consistent in the set of completed queries. For example, Hive 2.3.3 on MR3 takes over 12,000 seconds on the Red cluster because query 16 and 94 fail with a timeout after 3600 seconds, thus accounting for nearly two thirds of the total running time. Nevertheless we can make a few interesting observations:
- Hive 3.1.0 on MR3 finishes all the queries the fastest on the Red and Gold clusters. In particular, it achieves a reduction of 25% to 35% in the total running time when compared with Hive 3.1.0 on Tez. The reduction is particularly significant because it partially attests to the efficiency of MR3 as an alternative execution engine to Tez.
- On the Indigo cluster, Hive-LLAP of HDP 3.0.1 and Hive 3.1.0 on MR3 are the two fastest systems. Note that Hive-LLAP of HDP 3.0.1 fails on query 78 while Hive 3.1.0 on MR3 spends about 760 seconds on it. Hence the gap between their running times is in effect about 300 seconds only.
- SparkSQL is the slowest on all the three clusters. This is not because some queries fail with a timeout, but because almost all queries just run slow.
- Hive 3.1.0 on Tez is fast enough to outperform Presto 0.203e and SparkSQL 2.2.0. Similarly Hive on Tez in HDP 3.0.1 is fast enough to outperform Presto 0.208e and SparkSQL 2.3.1.
Analysis 3. Ranks for individual queries
In order to gain a sense of which system answers queries fast, we rank all the systems according to the running time for each individual query. The system that completes executing a query the fastest is assigned the highest place (1st) for the query under consideration. If a system does not compile or fails to complete executing a query, it is assigned the lowest place (6th) for the query under consideration. In this way, we can evaluate the six systems more accurately from the perspective of end users, not of system administrators.
Here is the result from the Red cluster:
- From left to right, the column corresponds to: Hive-LLAP of HDP 2.6.4, Presto 0.203e, SparkSQL 2.2.0, Hive 3.1.0 on Tez, Hive 3.1.0 on MR3, Hive 2.3.3 on MR3.
- The first place to the last place is colored in dark green (first), green, light green, light grey, grey, dark grey (last).
- Hive on Tez or MR3 is generally slow on the first few queries because its starts with no active containers and is assigned new containers only after the first query is submitted. The other systems, however, start with pre-warmed containers/workers and thus tend to run fast on the first few queries.
![]()
![]()
We observe that Hive-LLAP of HDP 2.6.4 dominates the competition: it places first for 60 queries and second for 12 queries. Next comes Hive 3.1.0 on MR3, which places first for 22 queries and second for 43 queries. Presto 0.203e places first for 9 queries, but places second only for 6 queries. Note that while Hive-LLAP places first for the most number of queries, it also places last for 10 queries. In contrast, Hive 3.1.0 on MR3 does not place last for any query.
From the Gold cluster, a noticeable change emerges:
![]()
![]()
Hive-LLAP of HDP 2.6.4 still places first for the most number of queries (39 queries, down from 60 queries on the Red cluster), but it also places last for 14 queries (up from 10 queries on the Red cluster). Hive 3.1.0 on MR3 places first for 28 queries and second for 34 queries, and place last only for query 16. (The four systems based on Hive all fail on query 16 whereas Presto 0.203e finishes it in 139 seconds.) Overall Hive 3.1.0 on MR3 is comparable to Hive-LLAP of HDP 2.6.4: Hive 3.1.0 on MR3 places first or second for a total of 62 queries, whereas Hive-LLAP of HDP 2.6.4 places first or second for a total of 60 queries. Incidentally SparkSQL 2.2.0 places first only for query 41, on both Red and Gold clusters.
The result from the Indigo cluster is especially important for the comparison between Hive-LLAP and Hive on MR3 because both systems are based on the same version of Hive, namely Hive 3.1.0. Presto and SparkSQL are also newer versions, so the result reflects the current state of each SQL-on-Hadoop system more accurately than from the Red and Gold clusters. Here is the result from the Indigo cluster:
- From left to right, the column corresponds to: Hive-LLAP of HDP 3.0.1, Presto 0.208e, SparkSQL 2.3.1, Hive 3.1.0 on Tez, Hive 3.1.0 on MR3, Hive 2.3.3 on MR3.
![]()
![]()
We observe that Hive 3.1.0 on MR3 is now slightly ahead of Hive-LLAP of HDP 3.0.1 in performance: Hive 3.1.0 on MR3 places first for 41 queries and second for 34 queries, whereas Hive-LLAP of HDP 3.0.1 places first for 36 queries and second for 49 queries. For Presto .208e, there is not much difference from the previous result based on Presto .203e. For SparkSQL 2.3.1, it still remains as the slowest among all the systems. Incidentally it still places first for query 41.
Summary of sequential tests
From our analysis above, we see that those systems based on Hive are indeed strong competitors in the SQL-on-Hadoop landscape, not only for their stability and versatility but now also for their speed. We summarize the results of sequential tests as follows:
- Hive-LLAP and Hive on MR3 are the two fastest SQL-on-Hadoop systems.
- Under the same configuration, Hive on MR3 runs consistently faster than Hive on Tez.
- Presto is stable and runs much faster than SparkSQL, but not as fast as Hive-LLAP or Hive on MR3 on average.
- SparkSQL running on top of vanilla Spark is very slow in comparison with Hive and Presto. Our experimental results suggest that in a computing environment in which Hive or Presto is readily available, there is no need to use SparkSQL at all.
Part II. Results of concurrency tests
In order to check if a SQL-on-Hadoop system is ready for production environments, we should test it for performance, stability, and scalability in multi-user environments in which many queries run concurrently, or by running concurrency tests. In our experiment, we choose a concurrency level from 8 to 16 and start as many Beeline or Presto clients (from 8 clients up to 16 clients), each of which submits 17 queries, query 25 to query 40, from the TPC-DS benchmark. For each run, we measure the longest running time of all the clients. Since the cluster remains busy until the last client completes the execution of all its queries, the longest running time can be thought of as the cost of executing queries for all the clients. If any query from any client fails, we regard the whole run as a failure. In this way, we test not only the performance but also the stability of a subject system in highly concurrent environments.
The selection of queries for concurrency tests is rather arbitrary, but still looks reasonable for our purpose. This is because every system under comparison successfully finishes all the 17 queries in the sequential test. Moreover the selection contains no long-running query (such as query 24), thereby lending itself well to concurrency tests.
Analysis 1. Running time
On the Red and Gold clusters, we compare three systems: Hive-LLAP of HDP 2.6.4, Presto 0.203e, and Hive 3.1.0 on MR3. We do not compare SparkSQL 2.2.0 which is too slow in sequential tests. The results for a concurrency level of 1 are obtained from the previous sequential tests. The last two columns show the reduction in the running time of Hive 3.1.0 on MR3 with respect to Hive-LLAP of HDP 2.6.4 and Presto 0.203e (in percentage).

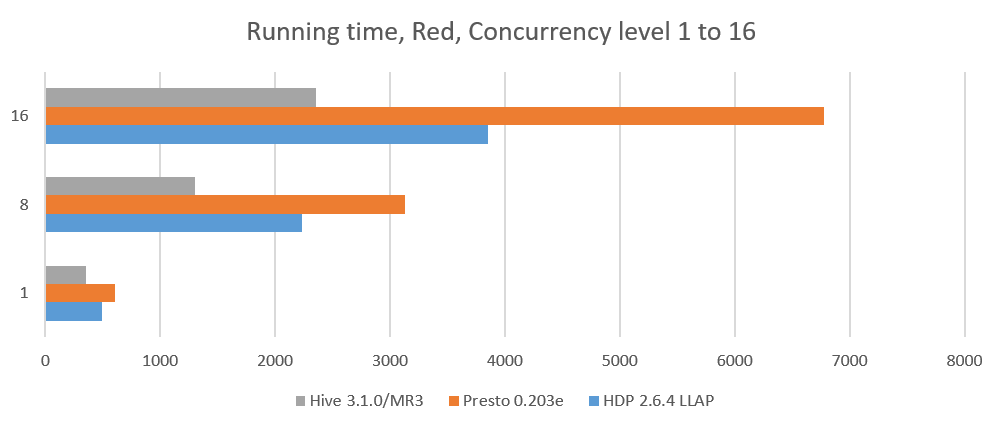

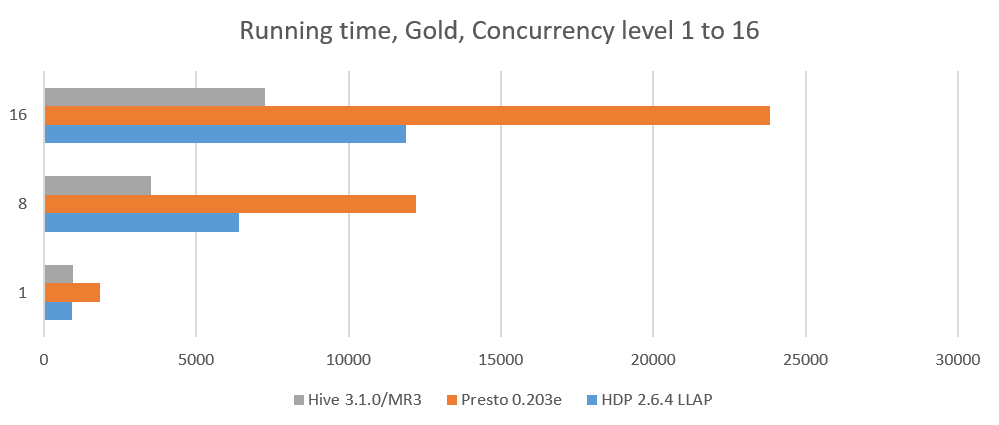
We observe that Hive 3.1.0 on MR3 achieves a significant reduction in the running time even with respect to Hive-LLAP of HDP 2.6.4, nearly doubling the throughput. Note that with a large concurrency level, Hive-LLAP (of any version of HDP) incurs a considerable overhead of maintaining ApplicationMasters because each active query requires a dedicated ApplicationMaster. For example, for a concurrency level of 64, Hive-LLAP consumes 64 * 2G = 128GB of memory for 64 ApplicationMasters alone (each of which is counted as a separate job by Hadoop). Hive on MR3 has no such issue because a single DAGAppMaster suffices for managing all concurrent queries.
On the Indigo cluster, we compare four systems: Hive-LLAP of HDP 3.0.1, Presto 0.208e, SparkSQL 2.3.1, and Hive 3.1.0 on MR3. The results for a concurrency level of 1 are obtained from the previous sequential tests.

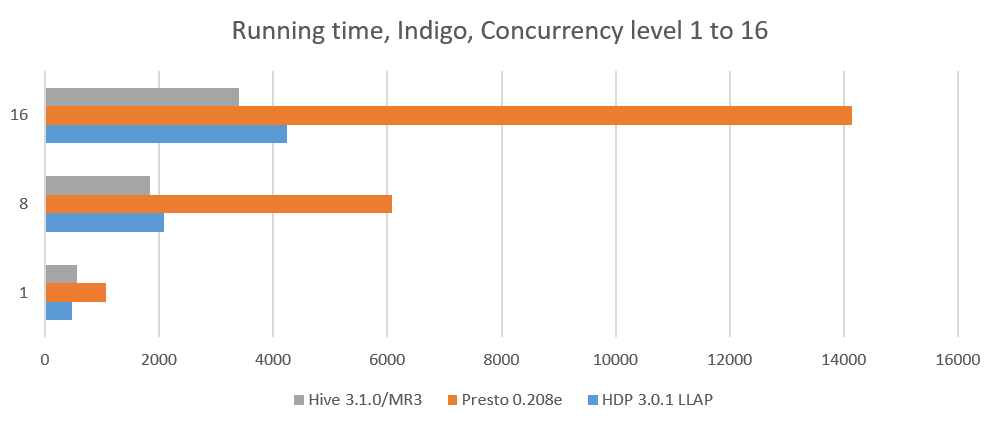
We observe that Hive on MR3 continues to far outperform Hive-LLAP, despite the fact that it is about 17 percent slower for the sequential execution with a single client. Moreover the reduction in the running time becomes more pronounced with higher concurrency levels, which suggests that Hive on MR3 exhibits excellent scalability.
Analysis 2. Concurrency factor
In our concurrency tests, we derive from the running time a new metric, called concurrency factor, quantifying the overall efficiency in managing concurrent queries.
- concurrency factor = running time in a concurrency test / (concurrency level * running time in an equivalent sequential test)
Thus a concurrency factor indicates ‘‘how long it takes to finish a single query in a concurrency test (or in a concurrent environment) relative to the time for finishing the same query in a sequential test (or in a single-user environment).’’ Here are a few examples:
- A concurrency factor of 0.4 means that a query taking 100 seconds in a sequential test takes 40 seconds on average in a concurrency test.
- For a system that makes no optimization in managing concurrent queries and just executes all incoming queries serially, we obtain a concurrency factor of 1. Hive on Tez has a concurrency factor close to 1 because no resources are shared between queries from different clients.
- For a system that caches the result of a query from a client and skips executing the same query from different clients, we sometimes obtain an ideal concurrency factor of ‘1 / concurrency level’.
Hive 3 with
hive.query.results.cache.enabledset to true may achieve an ideal concurrency factor under special circumstances. - For a system that incurs too much an overhead in running concurrent queries, we may observe a concurrency factor larger than 1.
A concurrency factor is a crucial metric for evaluating SQL-on-Hadoop systems in concurrent environments because it measures the architectural efficiency in managing concurrent queries. Note that it does not measure the efficiency of the execution pipeline for consuming an individual query. For example, upgrading the query optimizer in Hive would not have much impact on its concurrency factor because both ‘running time in a concurrency test’ and ‘running time in an equivalent sequential test’ in the formula shown above would equally decrease by the same factor. This implies that locally optimizing the execution pipeline is unlikely to affect the concurrency factor. Then we are led to conclude that in order to improve (i.e., decrease) the concurrency factor, we should rearchitect the whole system, which would be especially costly in practice for such mature systems as Hive, Presto, and SparkSQL. For this reason, we will see no major change in the concurrency factor in any of these systems in the near future. In essence, the concurrency factor is determined primarily by design and architecture, rather than by implementation and optimization.
Below are concurrency factors derived from concurrency tests:
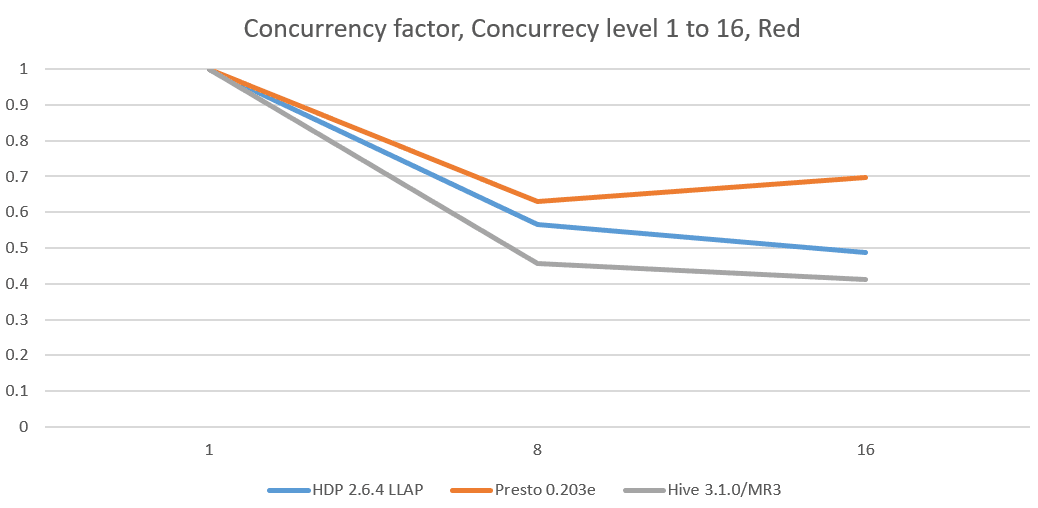
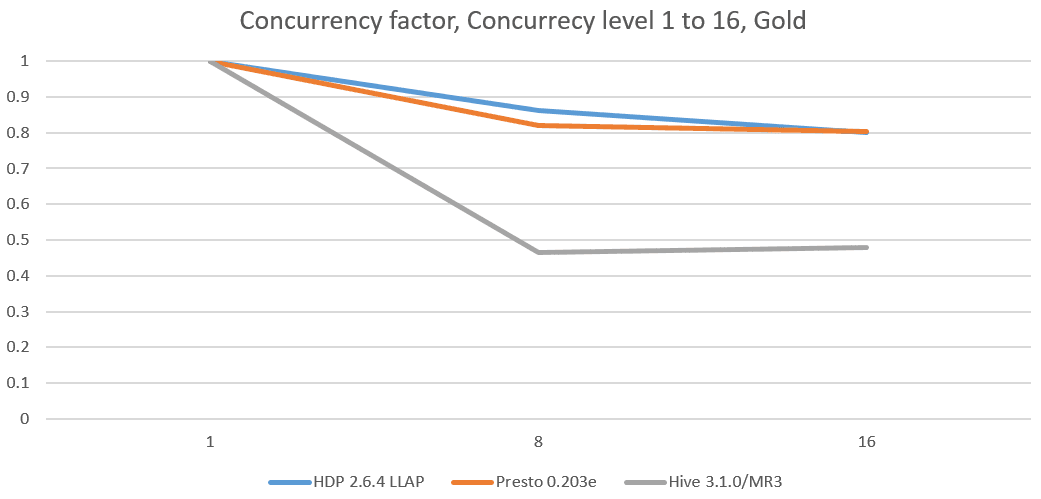
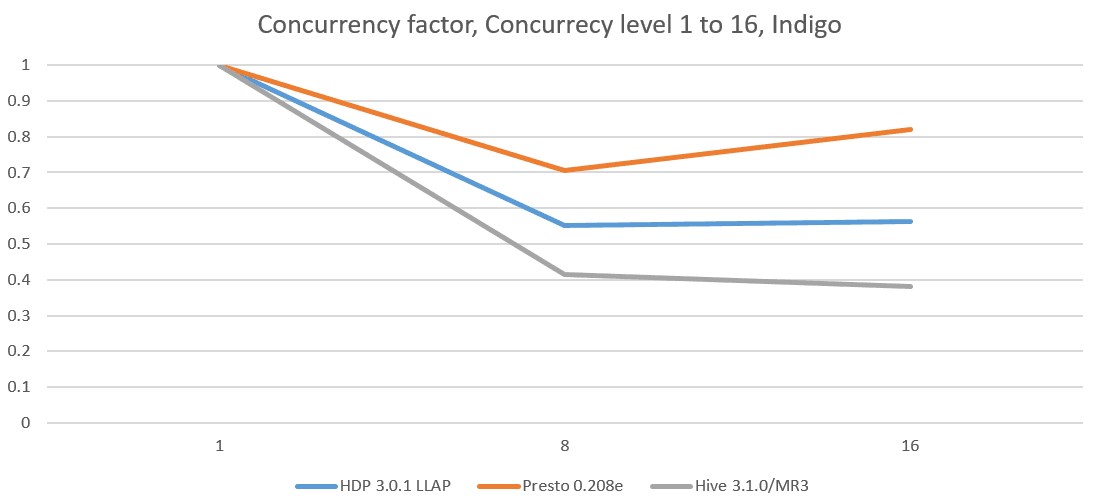
We observe that in every concurrency test, Hive on MR3 maintains the lowest concurrency factor, which stays around 0.4 across all the clusters. Moreover its concurrency factor stays nearly the same regardless of the concurrency level. On the Red and Indigo clusters, it concurrency factor even slightly decreases as the concurrency level increases.
Summary of concurrency tests
From our analysis above, we see that Hive on MR3 outshines other competitors in performance. It also shows excellent scalability. For example, Hive on MR3 scales successfully up to a concurrency level of 128 on the Red cluster without failing any single query. As is evident from the analysis of concurrent factors, the strength of Hive on MR3 stems from the design and architecture of MR3, not the use of Hive. After all, both Hive-LLAP and Hive on MR3 share the same code base to process individual queries. (For more details on the architectural difference between Hive-LLAP and Hive on MR3, we refer the reader to the following page: Comparison with Hive-LLAP.) We summarize the results of concurrency tests as follows:
- Hive on MR3 is the fastest SQL-on-Hadoop system for concurrent environments.
- As with single-user environments, SparkSQL is a poor choice for multi-user environments (when running on top of vanilla Spark). It is ironic to see that SparkSQL, once compared to a rabbit that made Hive look like a slow-moving tortoise, is now far behind Hive in the race.
Conclusion
We have evaluated several popular SQL-on-Hadoop systems with both sequential tests and concurrency tests. Depending on the background of the reader, the findings from the experiment may contradict previous beliefs on Hive, Presto, and SparkSQL. As the landscape SQL-on-Hadoop constantly changes, we will update experimental results with newer versions of SQL-on-Hadoop systems in the future.