Hive on MR3 0.2 vs Hive-LLAP
May 19, 2018
Read in 11 minutes
NOTE: This article uses Hive 2.2.0 and 2.3.3 to compare Hive-LLAP and Hive on MR3. We refer the reader to an up-to-date summary of differences between Hive-LLAP and Hive on MR3: Comparison with Hive-LLAP.
Introduction
Hive running on top of MR3 0.2, or Hive-MR3 henceforth, supports LLAP (Low Latency Analytical Processing) I/O. In conjunction with the ability to execute multiple TaskAttempts concurrently inside a single ContainerWorker, the support for LLAP I/O makes Hive-MR3 functionally equivalent to Hive-LLAP. Hence Hive-MR3 can now serve as a substitute for Hive-LLAP in typical use cases.
Although the two systems are functionally equivalent, Hive-MR3 and Hive-LLAP are fundamentally different in their architecture. In the case of Hive-MR3, a single MR3 DAGAppMaster can execute multiple DAGs concurrently, thus eliminating the need for one DAGAppMaster per DAG as in Hive-LLAP (if HiveServer2 runs in shared session mode). More importantly, the DAGAppMaster has full control over all ContainerWorkers, thus eliminating the potential performance overhead due to lack of knowledge on their internal states. For example, the DAGAppMaster never sends more TaskAttempts than a ContainerWorker can accommodate, which implies that the logic for executing TaskAttempts inside a ContainerWorker is very simple.
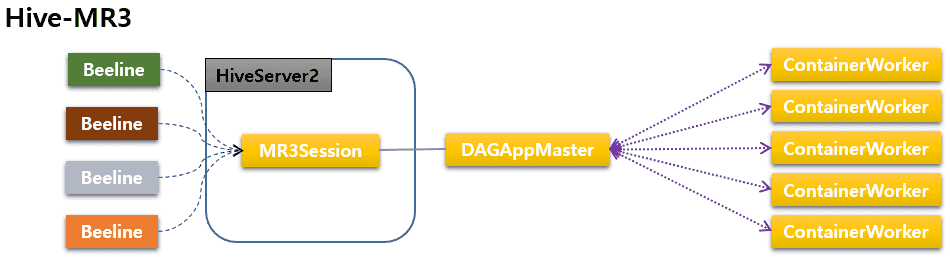
In contrast, Hive-LLAP executes multiple DAGs through an interaction between a group of Tez DAGAppMasters, which are effectively owned by HiveServer2, and another group of LLAP daemons, which are effectively owned by ZooKeeper. Since DAGAppMasters and LLAP daemons are independent processes (e.g., killing DAGAppMasters does not affect LLAP daemons, and vice versa), the interaction between the two groups is inevitably more complex than in Hive-MR3. In fact, all individual DAGAppMasters themselves are independent processes and compete for the service provided by LLAP daemons, thereby adding another layer of complexity in the architecture.
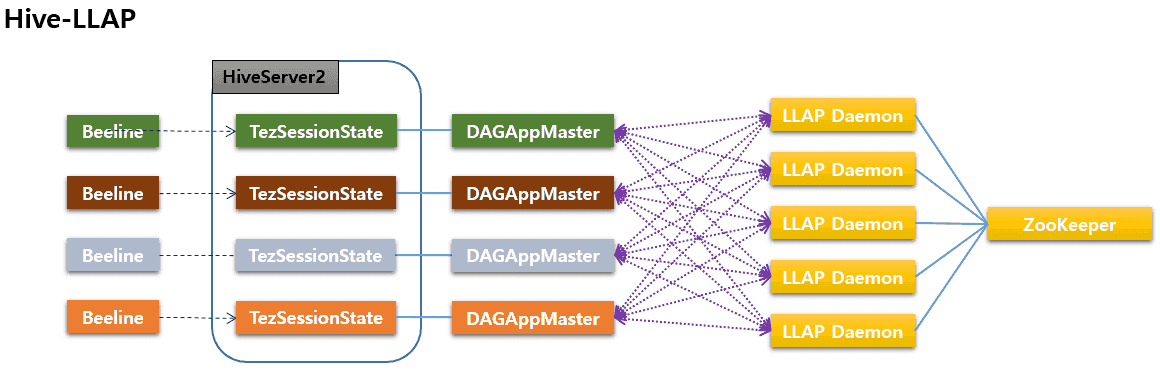
The difference in the architecture leads to distinct characteristics of the two systems. Below we present the pros and cons that the simplicity in the design of Hive-MR3 engenders with respect to Hive-LLAP. The comparison is based primarily on extensive experiments carried out in three different clusters under various configurations, involving both sequential and concurrent tests with the TPC-DS benchmark. In addition, we discuss those Hive-MR3 features that allow us to overcome a few known limitations of Hive-LLAP regarding usability. The details of all experiments are given after the analysis.
Pros of Hive-MR3 with respect to Hive-LLAP
1. Higher stability
The most important benefit of using Hive-MR3 is that queries are much less likely to fail than in Hive-LLAP:
- In sequential tests, Hive-LLAP fails on 25 query instances out of 10 * 60 = 600 query instances (10 runs with 60 query instances each), thus with a failure rate of 25/600 = 4.16%. In comparison, Hive-MR3 fails only on two query instances out of 14 * 60 = 840 query instances (14 runs with 60 query instances each), thus with a failure rate of 2/840 = 0.24%.

- In concurrent tests, Hive-LLAP fails on four runs out of a total of 12 runs, thus with a failure rate of 4/12 = 33.33%. In comparison, Hive-MR3 fails only on a single run out of a total of 16 runs, thus with a failure rate of 1/16 = 6.25%.

For Hive-LLAP in our experiments, it usually takes many runs (in a trial and error manner) to identify those queries that should be excluded from a sequential test. For Hive-MR3, this happens only once, and only with two queries.
2. Faster execution
The simplicity in the design of Hive-MR3 yields a noticeable difference in performance:
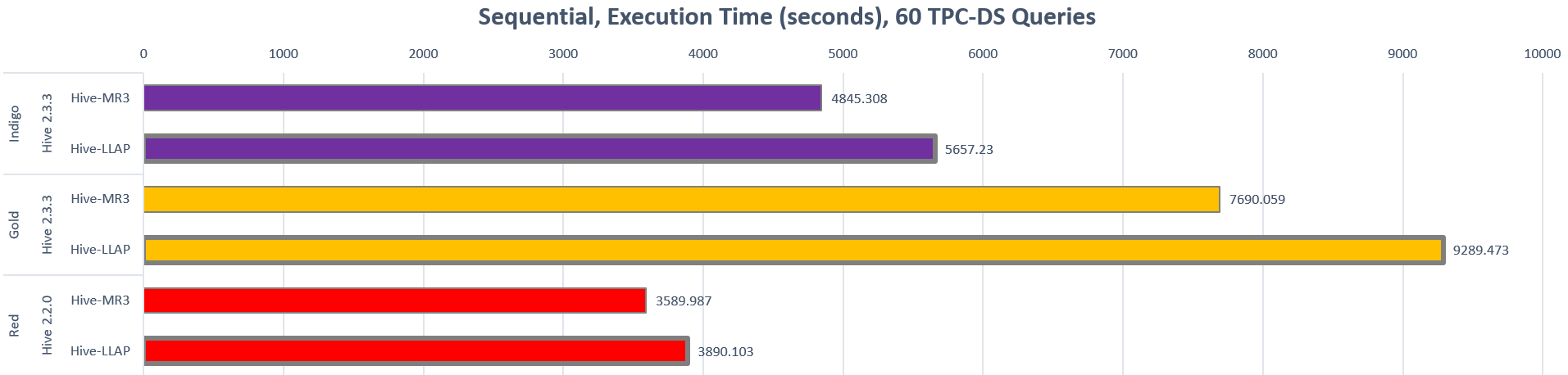
- In sequential tests, Hive-MR3 finishes a complete run of all queries in the TPC-DS benchmark up to 20.8% faster than Hive-LLAP.
- In concurrent tests, Hive-MR3 finishes 8 concurrent streams of 30 or 110 queries up to 22.04% faster than Hive-LLAP.
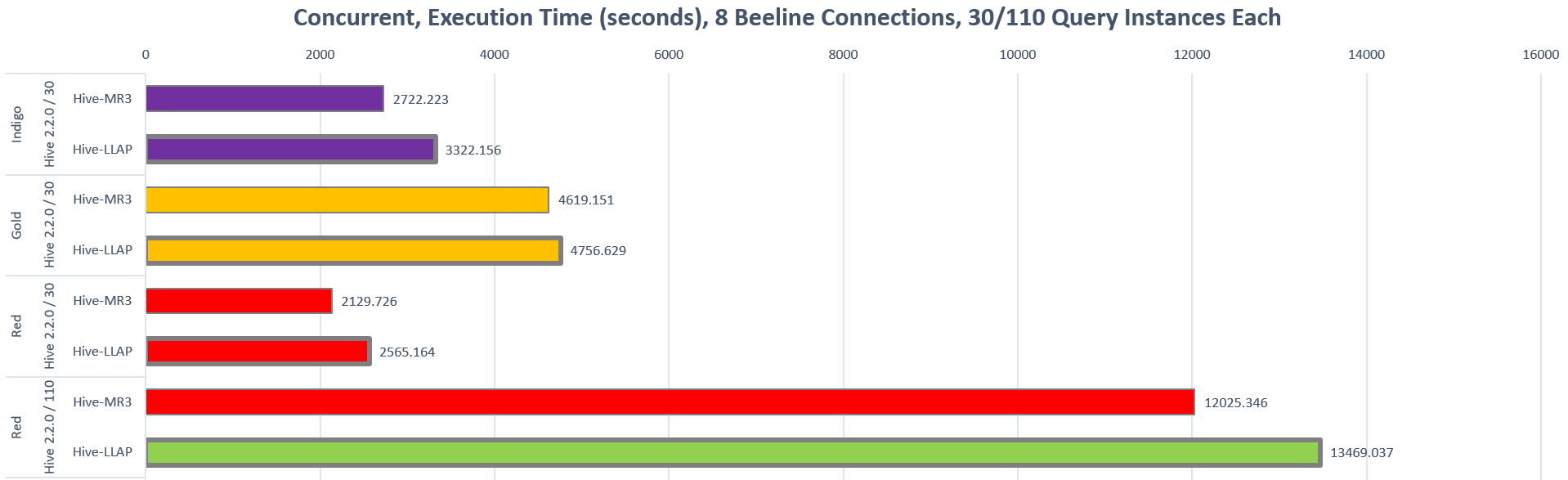
In particular, Hive-MR3 runs faster than Hive-LLAP in all test scenarios.
3. Elastic allocation of cluster resources
For Hive-LLAP, the administrator user should decide in advance the number of LLAP daemons and their resource usage after taking into account the plan for running the cluster. Once started, LLAP daemons do not release their resources, which comes with two undesirable consequences:
- When LLAP daemons are idle, their resources cannot be reassigned to busy applications in the same cluster.
- When LLAP daemons are busy, there is no way to exploit idle resources in the cluster.
These problems are particularly relevant to Hive-LLAP because LLAP daemons usually consume very large containers, often the largest containers that Yarn can allocate. In contrast, Hive-MR3 suffers from no such problems because ContainerWorkers are allocated directly from Yarn:
- In order to release idle ContainerWorkers more often, the user only needs to adjust the value for the configuration key
mr3.container.idle.timeout.msinmr3-site.xml. Alternatively the user can just kill idle ContainerWorkers manually. - When idle resources exist, Hive-MR3 automatically requests more resources on behalf of its ContainerWorkers.
In this way, Hive-MR3 cooperates with existing applications while trying to maximize its own resource usage.
4. Support for hive.server2.enable.doAs=true
In principle, Hive-MR3 always allows the user to set the configuration key hive.server2.enable.doAs to true
because it is just an ordinary application running on top of MR3.
When LLAP I/O is enabled in a secure cluster, however, setting hive.server2.enable.doAs to true can be a problem
if the LLAP I/O module caches data across many users with different access privileges.
This is also the reason why Hive-LLAP disallows hive.server2.enable.doAs set to true.
On the other hand, as long as LLAP I/O is disabled, hive.server2.enable.doAs in Hive-MR3 can be safely set to true.
Hence, for those environments in which 1) LLAP I/O is optional and 2) hive.server2.enable.doAs should be set to true,
Hive-MR3 is a better choice than the only alternative available, namely Hive-on-Tez.
For such environments, Hive-MR3 overcomes a well-known limitation of Hive-LLAP.
5. Better support for concurrency
In Hive-LLAP, the degree of concurrency is limited by the maximum number of Tez DAGAppMasters that can be created at once by Yarn.
This is because each running query requires a dedicated Tez DAGAppMaster for managing its TaskAttempts.
In practice, the administrator user can impose a hard limit on the number of concurrent queries
by setting the configuration key hive.server2.tez.sessions.per.default.queue in hive-site.xml to a suitable value.
In Hive-MR3,
if HiveServer2 runs in shared session mode,
the degree of concurrency is limited only by the amount of memory allocated to a single MR3 DAGAppMaster managing all concurrent queries.
The administrator user may also set the configuration key mr3.am.max.num.concurrent.dags in mr3-site.xml to specify the maximum number of concurrent queries.
Note that HiveServer2 can also run in individual session mode, in which case the degree of concurrency is limited by the maximum number of MR3 DAGAppMasters like in Hive-LLAP.
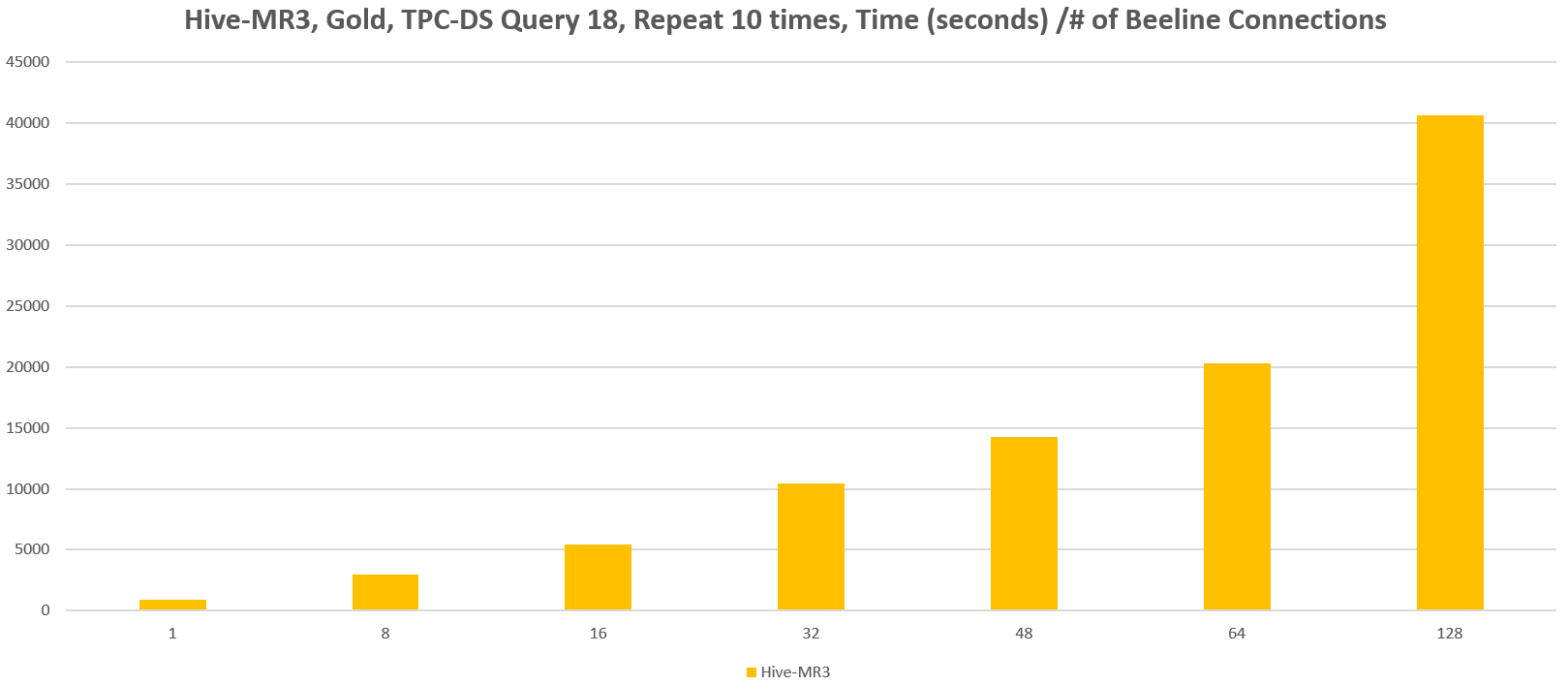
In comparison with Hive-LLAP, the use of a single DAGAppMaster brings an advantage to Hive-MR3: in the presence of many concurrent queries, Hive-MR3 consumes much less memory for a single MR3 DAGAppMaster than Hive-LLAP consumes for as many Tez DAGAppMasters. In our experiment, a single MR3 DAGAppMaster of 32GB is enough to run 128 concurrent queries from the same number of Beeline connections (each of which repeats 10 times the query 18 of the TPC-DS benchmark). For Hive-LLAP, we should consume 4GB * 128 = 512GB of memory for Tez DAGAppMasters alone (on the assumption that each Tez DAGAppMaster consumes 4GB of memory).
Moreover we observe virtually no performance penalty for sharing a DAGAppMaster for many concurrent queries. This is because the computational load on the DAGAppMaster is proportional not to the number of concurrent queries but to the total number of active TaskAttempts, which cannot exceed the limit determined by the total cluster resources.
6. Miscellaneous
- As it does not require ZooKeeper, Hive-MR3 is easier to deploy than Hive-LLAP.
- By taking advantage of LocalProcess mode in MR3, HiveServer2 can start a DAGAppMaster outside the Hadoop cluster, e.g., on the same machine where HiveServer2 itself runs. This feature is also useful for testing and debugging because the log file for the DAGAppMaster is easily accessible.
- HiveCLI can use LLAP I/O. Note, however, that different instances of HiveCLI do not share the cache for LLAP I/O because each instance maintains its own set of ContainerWorkers.
Cons of Hive-MR3 with respect to Hive-LLAP
1. No LLAP daemons
Since ContainerWorkers can execute TaskAttempts from different DAGs and LLAP I/O is implemented with a DaemonTask, Hive-MR3 runs no daemon processes like LLAP daemons in Hive-LLAP. While this is a unique feature of Hive-MR3, it is also a shortcoming that prevents Hive-MR3 from serving as a true substitute for Hive-LLAP in every environment. Specifically Hive-MR3 cannot serve I/O requests from external sources (such as Spark) because ContainerWorkers communicate only with an MR3 DAGAppMaster. In contrast, LLAP daemons in Hive-LLAP can serve such I/O requests.
2. Simple strategy for scheduling Tasks
Currently Hive-MR3 lacks a sophisticated strategy for scheduling Tasks. For example, it never cancels long-running Tasks in order to quickly finish a short-lived Task from the last stage of a query. As a result, all queries are assigned the same priority and processed in a FIFO fashion. As the use of a single strategy for scheduling Tasks is not an inherent weakness of Hive-MR3, we plan to incorporate new strategies in a future release.
3. Miscellaneous
- Due to the limitation of Tez runtime which is not designed for the concurrent execution of multiple TaskAttempts in a single container, Hive-MR3 may report the statistics on a query only approximately when running multiple queries concurrently.
- Currently Hive-MR3 does not allow the user to kill specific queries. MR3, however, allows the user to kill specific DAGs, so HiveServer2 can be extended to relay the kill request from the user to the DAGAppMaster.
Experiments
Now we describe the details of all experiments: clusters, configurations, and results.
Clusters for experiments
We run the experiment in three different clusters: Indigo, Gold, and Red. All the machines in the three clusters share the following properties:
- 2 x Intel(R) Xeon(R) X5650 CPUs
- 96GB of memory on Indigo and Gold, 192GB of memory on Red
- 6 x 500GB HDDs
- 10 Gigabit network connection
- HDFS replication factor of 3
- Hadoop 2.7.3 running Hortonworks Data Platform (HDP) 2.6.4
| Indigo | Gold | Red | |
|---|---|---|---|
| Number of master nodes | 2 | 2 | 1 |
| Number of slave nodes | 20 | 40 | 10 |
| Scale factor for the TPC-DS benchmark | 3TB | 10TB | 1TB |
| Memory size for Yarn on a slave node | 84GB | 84GB | 168GB |
| Security | No | No | Kerberos |
Experiment configurations
For a sequential run, we submit 60 queries from the TPC-DS benchmark, starting from query 3 and ending with query 98, with a single Beeline connection. If a query fails, we exclude it from the set of queries and start over. We repeat this procedure until the last query succeeds.
For a concurrent run, we simultaneously start 8 Beeline connections, each of which repeats a total of 10 times a sequence consisting of queries 18, 19, and 20, thus executing 30 query instances. On the Red cluster, we try an additional experiment configuration in which each Beeline connection repeats a total of 10 times a sequence of 11 queries (query 12 to query 27), thus executing 10 * 11 = 110 query instances. Unlike sequential runs, we regard the whole run as a failure if any Beeline connection fails to complete all the queries. This is because we cannot compare outcomes from different numbers of Beeline connections (e.g., 8 Beeline connections for Hive-MR3 and 6 Beeline connections for Hive-LLAP).
We use Hive-MR3 based on Hive 2.2.0 or Hive 2.3.3. (We do not use Hive 2.3.3 for all experiments because of the bug reported in HIVE-18786.) We use Tez runtime 0.9.1. For testing Hive-LLAP, we use the same installation for Hive-MR3 which includes Hive-LLAP as well.
For each scenario, Hive-MR3 and Hive-LLAP use common configuration files for hive-site.xml and tez-site.xml.
The configuration files used in our experiments can be found in the Hive-MR3 release:
conf/tpcds/hive2for Hive-MR3 based on Hive 2.3.3conf/tpcds/hive4for Hive-MR3 based on Hive 2.2.0conf/tpcds/mr3for MR3 0.2conf/tpcds/tez3for Tez runtime 0.9.1
Experimental results
For the reader's perusal, we attach two tables containing the details of all experimental results: Sequential for sequential runs and Concurrent for concurrent runs.
- Container/daemon memory: Size of a ContainerWorker in Hive-MR3; size of an LLAP daemon in Hive-LLAP.
- Number of executors: Number of concurrent TaskAttempts in a ContainerWorker in Hive-MR3; number of executors in an LLAP daemon in Hive-LLAP. x1 for Hive-MR3 means that a ContainerWorker executes one TaskAttempt at a time.
- Headroom memory: Size of Java VM overhead.
- Cache size of LLAP I/O: Cache size when LLAP I/O is enabled.
- Running time (seconds): Green color means successful runs, and red color means unsuccessful runs in which some queries fail. Queries marked with FAIL fail to finish.
- Best running time with no failures: The shortest running time when all queries succeed.
- Speed-up against Hive-LLAP (%): Speed-up calculated from the best running times of Hive-MR3 and Hive-LLAP.
Here is a link to [Google Docs].