Performance Evaluation of Hive on MR3 0.1 (Part II)
Apr 2, 2018
Read in 8 minutes
In order to check if Hive running on top of MR3, or Hive-MR3 henceforth, is ready for production environments, we should test it for performance, stability, and scalability in multi-user environments in which many queries run concurrently. While Hive-on-Tez does a good job in multi-user environments, an analysis of the architecture of Tez reveals that we can further improve its support for multi-user environments by allowing a single DAGAppMaster to manage multiple concurrent DAGs. One of the design goals of MR3 is to overcome this limitation of Tez so as to better support multi-user environments as a new execution engine of Hive.
In this article, we report the result of testing Hive-MR3 and Hive-on-Tez on the TPC-DS benchmark in a concurrent execution setting. As in the previous experiment for a sequential execution setting, we use exactly the same configuration files for both Hive-MR3 and Hive-on-Tez. We use the following two combinations of Hive-MR3 and Tez runtime:
- Hive-MR3 based on Hive 1.2.2 + Tez 0.9.1
- Hive-MR3 based on Hive 2.1.1 + Tez 0.9.1
We do not use Hive-MR3 based on Hive 2.3.2 because of a stability issue in Hive 2.3.2 (HIVE-18786).
We run the experiment in the same clusters as before: Red and Gold. All the machines in both clusters are identical:
- 2 x Intel(R) Xeon(R) X5650 CPUs
- 96GB memory
- 6 x 500GB HDDs
- 10 Gigabit network connection
The Red cluster is configured as follows:
- One master and 10 slaves
- Hadoop 2.7.1
- HDFS replication factor of 3
- Security with Kerberos
- Dataset with a scale factor of 1TB for the TPC-DS benchmark
- 80GB memory for Yarn on every slave machine
The Gold cluster is configured as follows:
- Two masters (with a secondary namenode) and 40 slaves
- Hadoop 2.7.1
- HDFS replication factor of 3
- No security
- Dataset with a scale factor of 10TB for the TPC-DS benchmark
- 80GB memory for Yarn on every slave machine
For each combination of Hive-MR3 and Tez runtime,
we try MR3 and Tez as the execution engine (by setting hive.execution.engine to mr3 or tez in hive-site.xml).
For each run, we simultaneously start 16 Beeline connections,
each of which repeats a total of 10 times a sequence consisting of query 18, query 19, and query 20 from the TPC-DS benchmark (and thus executes 30 instances of the three queries).
We reuse configuration settings in the directory conf/tpcds of the Hive-MR3 release for all runs, with the following exceptions:
- Each container uses 4GB memory in the Red cluster and 5GB memory in the Gold cluster, respectively.
- We allocate 32GB memory to each MR3 DAGAppMaster. As a side note, allocating 16GB memory makes little difference in experimental results.
- For those runs in the Gold cluster, we run MR3 DAGAppMasters in LocalProcess mode.
Since we are interested only in the relative performance of MR3 with respect to Tez, our experiment does not enable various optimization features found in Hive 2.x.
Experimental results
For each run, we measure the longest running time of all the Beeline connections. Since the cluster remains busy until the last Beeline connection completes the execution of all its queries, the longest running time can be thought of as the cost of executing queries for all the Beeline connections.
The following chart shows the longest running time (in seconds) for each run in the Red cluster:

The following chart shows the longest running time (in seconds) for each run in the Gold cluster:
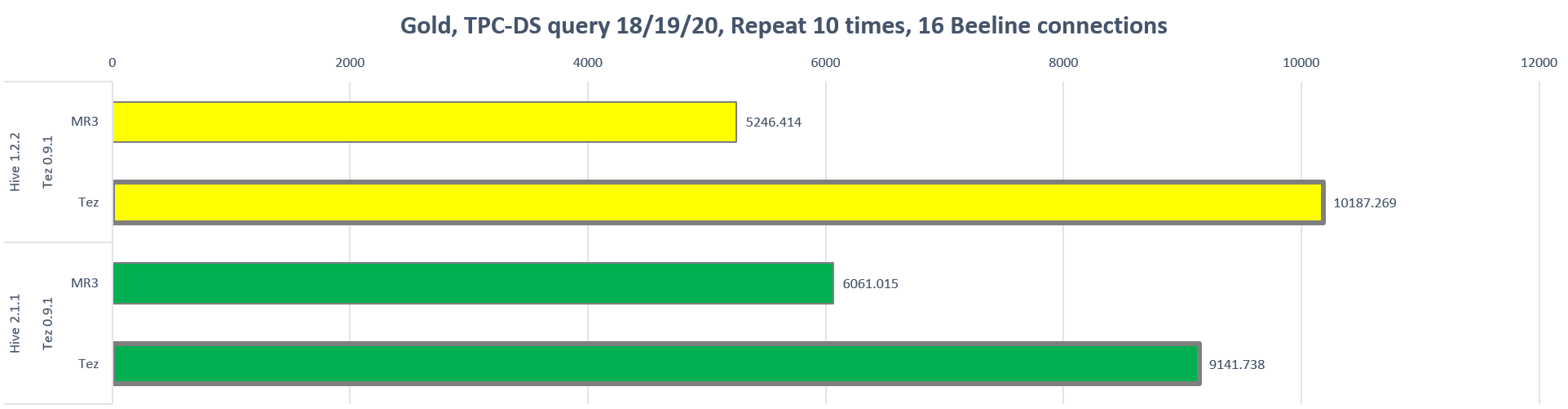
The following table shows the reduction in the longest running time (in percentage) when switching from Tez to MR3:
| Cluster | Hive-MR3 based on | Tez runtime | Reduction in the longest running time |
|---|---|---|---|
| Red | Hive 1.2.2 | Tez 0.9.1 | 29.62% |
| Hive 2.1.1 | Tez 0.9.1 | 21.94% | |
| Gold | Hive 1.2.2 | Tez 0.9.1 | 48.50% |
| Hive 2.1.1 | Tez 0.9.1 | 33.70% |
Analysis of experimental results
We observe that across all the combinations of Hive-MR3 and Tez runtime in both clusters, Hive-MR3 achieves a significant reduction in the cost of executing queries. For example, Hive-MR3 based on Hive 1.2.2 reduces the longest running time by 48.50% (from 10187.269 seconds to 5246.414 seconds) in the Gold cluster, thereby almost doubling the throughput. Hence MR3 has a clear advantage over Tez in multi-user environments as well.
The reduction in the cost is partially due to an increase in the speed of the execution engine itself, but is mainly due to a much better utilization of computing resources in the course of managing an influx of concurrent queries. Intuitively the speed of the execution engine accounts for only an average reduction of 9.31% in the cost (from the previous experiment in a sequential execution setting), so a reduction up to 48.50% is feasible only with a much better utilization of computing resources. In Hive-MR3, HiveServer2 running in shared session mode achieves this goal by trying to keep all ContainerWorkers busy.
To explain how Hive-MR3 makes a much better utilization of computing resources than Hive-on-Tez, see the following heat map of containers over time when running the same sequence of queries 18 to 20 in a single session:
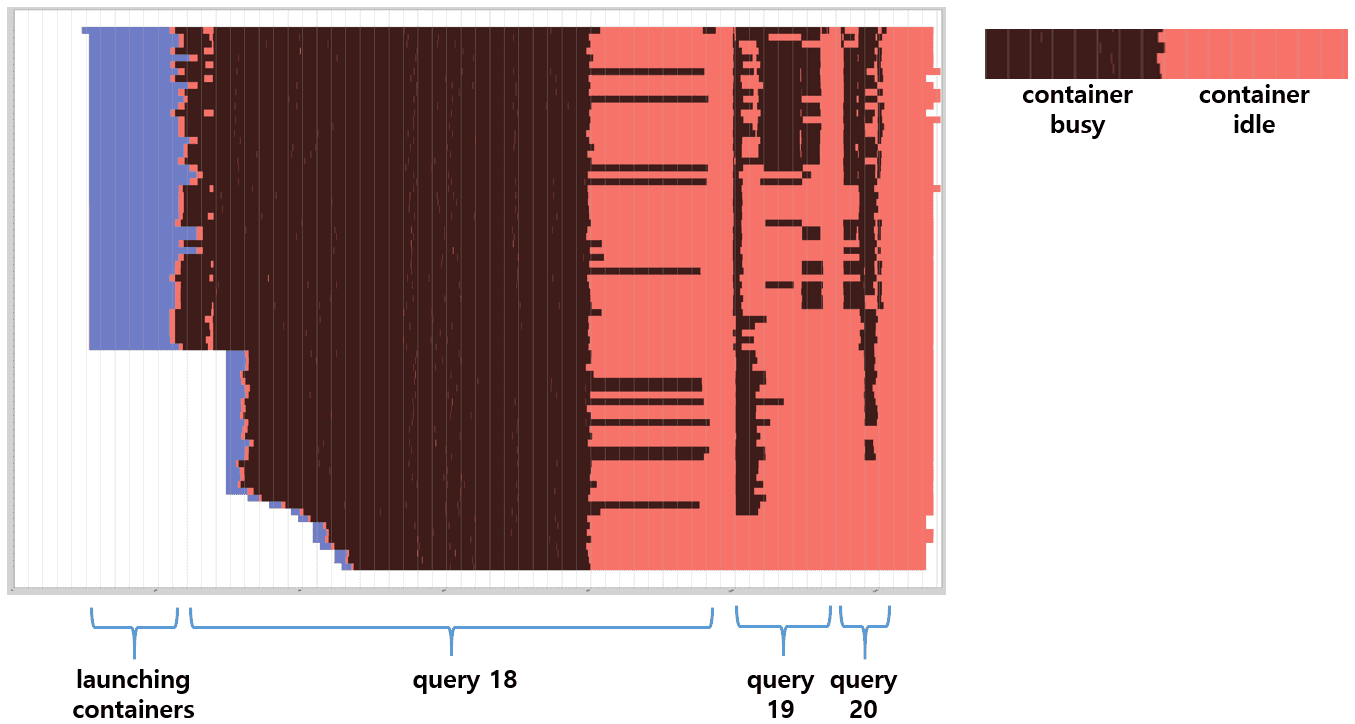
Because of the difference in the complexity of DAGs, the session allocates many containers for query 18 in the beginning, but the majority of these containers stay almost idle once query 18 reaches its last stage. In the case of Hive-on-Tez, such idle containers cannot be reassigned to another concurrent session because of the limitation of Tez DAGAppMasters, each of which maintains its own island of containers. In contrast, Hive-MR3 can immediately reassign such containers to serve other queries from concurrent sessions if all sessions share a common DAGAppMaster, or if HiveServer2 runs in shared session mode. For this reason, MR3 ContainerWorkers in our experiment are almost always busy serving different queries from different sessions.
Analysis of turnaround time
The use of shared session mode for HiveServer2 in Hive-MR3 has an important implication on end user experience: the turnaround time for a query is much more predictable than in Hive-on-Tez. In the case of Hive-on-Tez, all Beeline connections compete with each other for computing resources because 1) each Beeline connection runs its own DAGAppMaster, and 2) containers are not shared among DAGAppMasters. As a result, a fresh Beeline connection in a busy cluster may have to wait for long until it acquires computing resources for creating containers. In the case of Hive-MR3 (running HiveServer2 in shared session mode), all ContainerWorkers are effectively shared among all concurrent Beeline connections. As a result, even a fresh Beeline connection has a reasonable chance of executing its queries without too much delay.
Our experiment indeed confirms these properties of Hive-MR3 and Hive-on-Tez. The following graph shows the progress of every Beeline connection in the Red cluster:
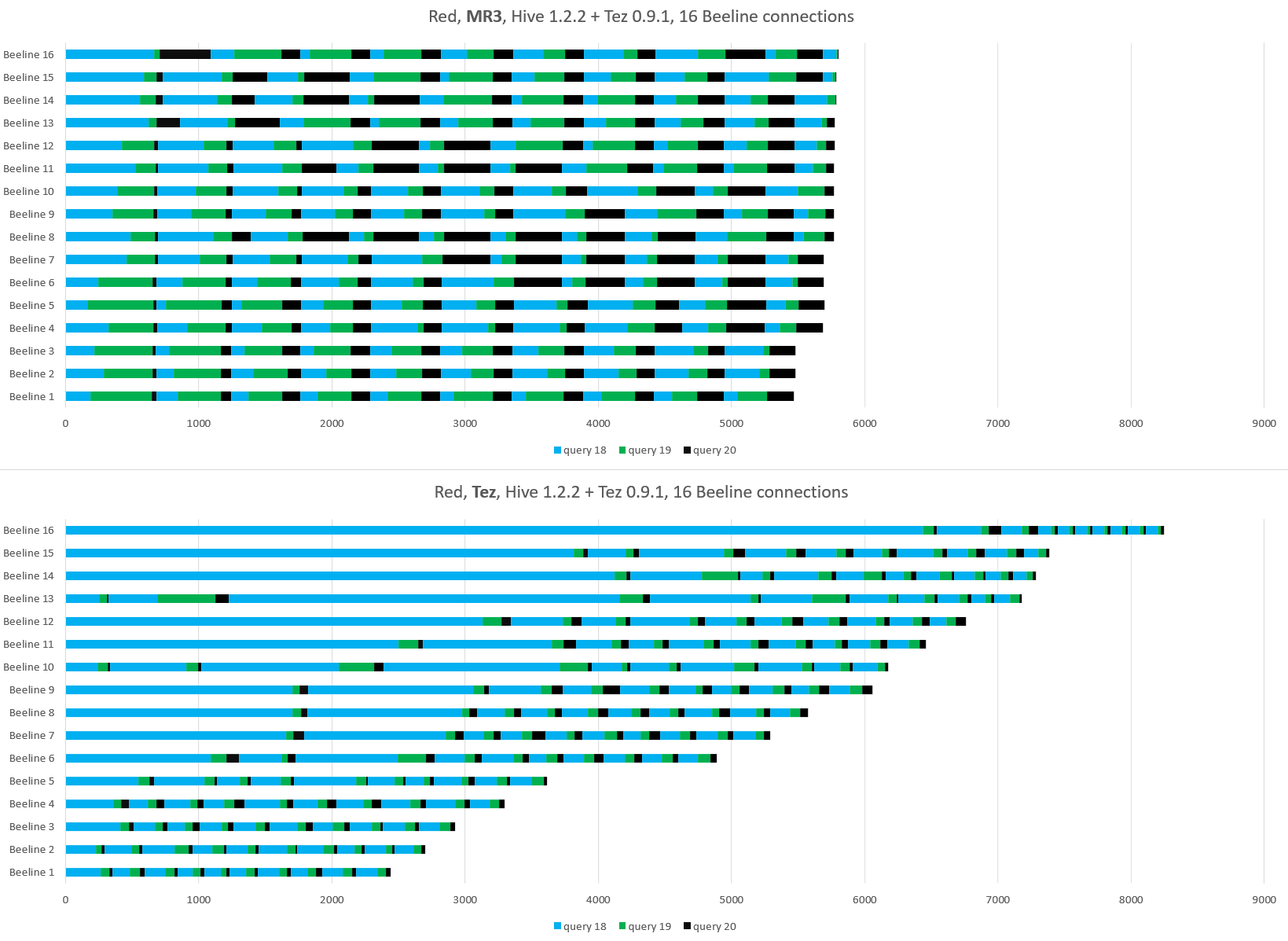
With Hive-MR3, all Beeline connections make steady progress at a similar pace, and we observe a regular pattern in the distribution of turnaround times regardless of the state of the cluster at the point of creating Beeline connections. With Hive-on-Tez, however, those lucky Beeline connections (e.g., Beeline 1 and Beeline 2) that acquire computing resources in the beginning quickly finish their queries, while those unlucky Beeline connections (e.g., Beeline 15 and Beeline 16) wait for long before starting to execute their queries. As a result, the distribution of turnaround times is determined to a large extent by the state of the cluster at the point of creating Beeline connections.
We observe the same behavior of Hive-MR3 and Hive-on-Tez from the Gold cluster:
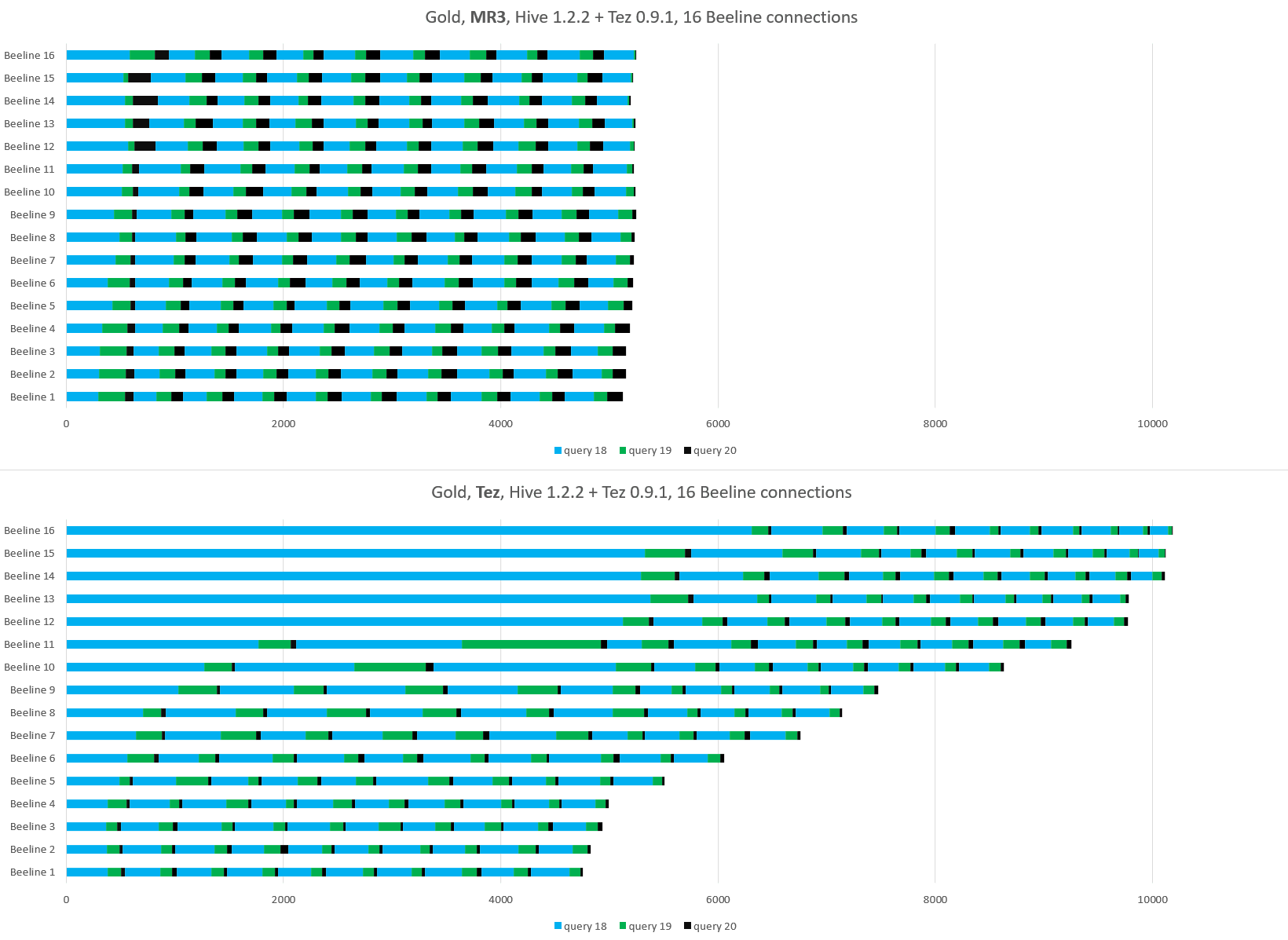
The bottom line is that with Hive-MR3, end users can make a reasonable prediction of the turnaround time based on the overall state of the cluster: the busier the cluster is, the longer the turnaround time will be. The specific details of the cluster state, such as the current distribution of computing resources among active queries, can just be ignored.
Result of repeating the same query
To further test Hive-MR3 and Hive-on-Tez, we run another experiment in which each of 16 Beeline connections repeats a total of 20 times the same query 18 from the TPC-DS benchmark. As in the previous experiment, we report the longest running time of all the Beeline connections.
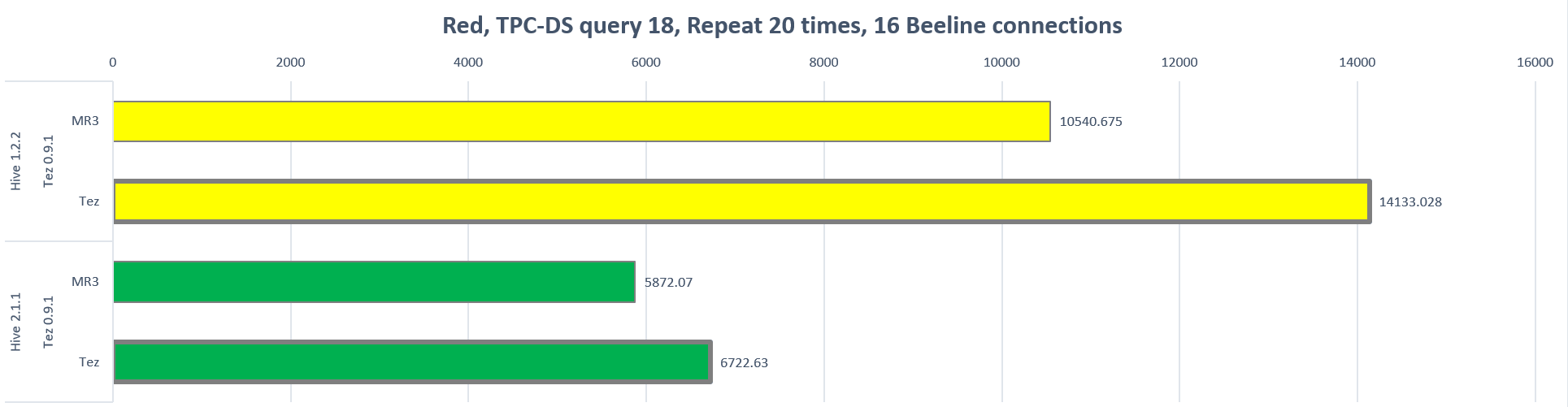
The following chart shows the longest running time (in seconds) for each run in the Red cluster:
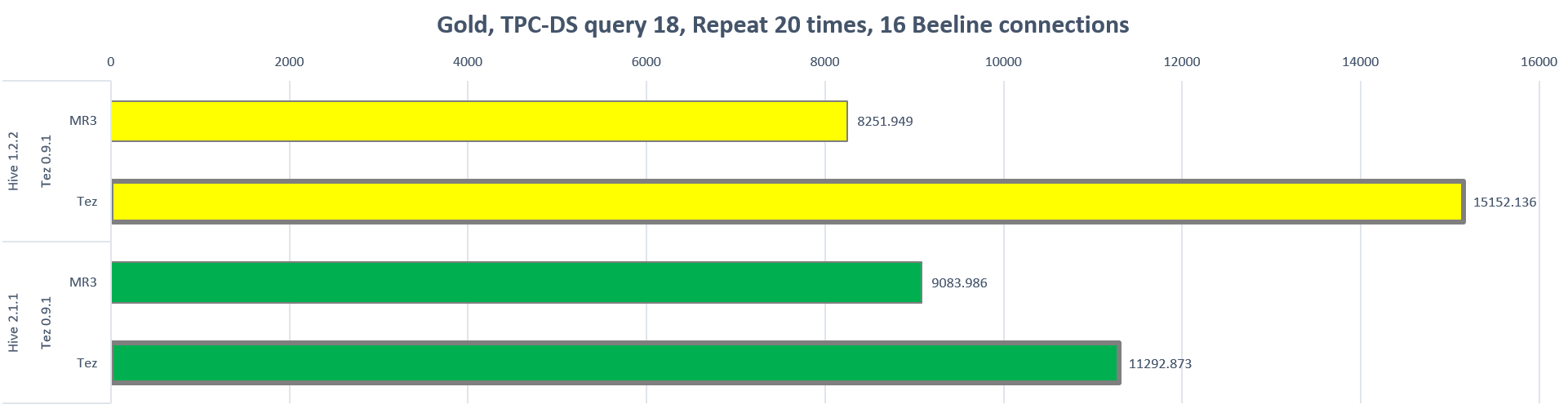
The following chart shows the longest running time (in seconds) for each run in the Gold cluster:
The following table shows the reduction in the longest running time (in percentage) when switching from Tez to MR3:
| Cluster | Hive-MR3 based on | Tez runtime | Reduction in the longest running time |
|---|---|---|---|
| Red | Hive 1.2.2 | Tez 0.9.1 | 25.42% |
| Hive 2.1.1 | Tez 0.9.1 | 12.65% | |
| Gold | Hive 1.2.2 | Tez 0.9.1 | 45.54% |
| Hive 2.1.1 | Tez 0.9.1 | 19.56% |
Note that the reduction in the longest running time is slightly smaller than in the previous experiment. For example, for Hive-MR3 based on Hive 2.1.1 in the Gold cluster, the reduction in the longest running time decreases from 33.70% in the previous experiment to 19.56% in the new experiment. This is because now in Hive-on-Tez, executing only query 18 is more likely to keep containers busy than mixing queries 19 and 20 as well, as indicated in the previous heat map of containers. Nevertheless we observe the same pattern as in the previous experiment: Hive-MR3 achieves a significant reduction in the cost of executing queries. On the whole, it is in a concurrent execution setting that Hive-MR3 manifests its strength particularly well.