Performance Evaluation of Trino and Hive on MR3 using the TPC-DS Benchmark
Jan 7, 2024
Read in 5 minutes
Introduction
In our previous article, we evaluate the performance of Trino 418 and Hive on MR3 1.7 using the TPC-DS Benchmark with a scale factor of 10TB.
- In terms of the total running time, the two systems are comparable: Trino 7424 seconds vs Hive on MR3 7415 seconds.
- In terms of the geometric mean of running times, Trino is faster than Hive on MR3: Trino 21.75 seconds vs Hive on MR3 27.68 seconds.
- Trino returns wrong answers on query 23 after running for 1756 seconds.
- Trino fails to complete query 72 after running for 156 seconds.
In this article, we evaluate the performance of newer versions of the two systems:
- Trino 435 (released on December 13, 2023)
- Hive 3.1.3 on MR3 1.9 (released on January 7, 2024)
By conducting the experiment in the same cluster used in the previous evaluation, we can also assess the improvements in the newer versions. Both Trino and Hive on MR3 use Java 17.
Experiment Setup
Cluster
For the experiment, we use a cluster consisting of 1 master and 12 worker nodes with the following properties:
- 2 x Intel(R) Xeon(R) E5-2640 v4 @ 2.40GHz
- 256GB of memory
- 1 x 300GB HDD, 6 x 1TB SSDs
- 10 Gigabit network connection
In total, the amount of memory of worker nodes is 12 * 256GB = 3072GB. The cluster runs HDP (Hortonworks Data Platform) 3.1.4 and uses HDFS replication factor of 3.
TPC-DS benchmark
We use a variant of the TPC-DS benchmark introduced in the previous article which replaces an existing LIMIT clause with a new SELECT clause so that different results from the same query translate to different numbers of rows. The reader can find the set of modified TPC-DS queries in the GitHub repository.
The scale factor for the TPC-DS benchmark is 10TB.
We generate datasets in ORC with Snappy compression.
Configuration
For Trino, we use a JVM option -Xmx196G and choose the following configuration
after performance tuning:
memory.heap-headroom-per-node=58GB
query.max-total-memory=1680GB
query.max-memory-per-node=120GB
query.max-memory=1440GB
For Hive on MR3, we use the default configuration in the MR3 distribution
except that
we use a JVM option -Xmx86G for every worker and create two workers on each node.
Test
We sequentially submit 99 queries from the TPC-DS benchmark. We report the total running time, the geometric mean of running times, and the running time of each individual query.
In order to check the correctness, we report the number of rows from each query. If the result contains a single row, we report the sum of all numerical values in it.
Raw data of the experiment results
For the reader's perusal, we attach the table containing the raw data of the experiment results. Here is a link to [Google Docs].
Analysis
#1. Query completion
Hive on MR3 successfully completes all the queries,
whereas Trino still fails to complete query 72
with an error message Query exceeded per-node memory limit of 120GB.
This is a typical case in which Trino (or any MPP system without fault tolerance)
fails to complete a query because of lack of memory for holding intermediate data.
#2. Correctness
The two systems agree on the result except that Trino still returns no rows (wrong answers) on query 23 after running for 1783 seconds.
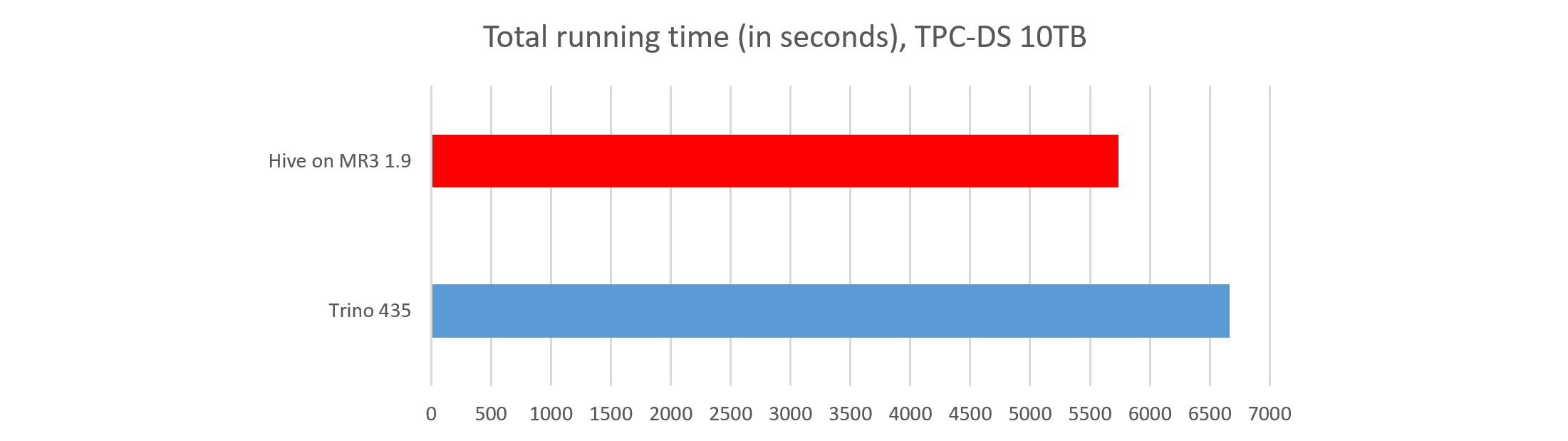
#3. Total running time
In terms of the total running time, Hive on MR3 is clearly faster than Trino.
- Trino finishes all the queries in 6667 seconds.
- Hive on MR3 finishes all the queries in 5739 seconds.
The total running time for Hive on MR3 includes about 120 seconds that is spent solely inside Beeline while fetching results from HiveServer2. For example, Beeline spends about 8 seconds to fetch 664,742 rows from HiveServer2 after executing query 11. Thus Hive on MR3 completes all the queries in approximately 5620 seconds.
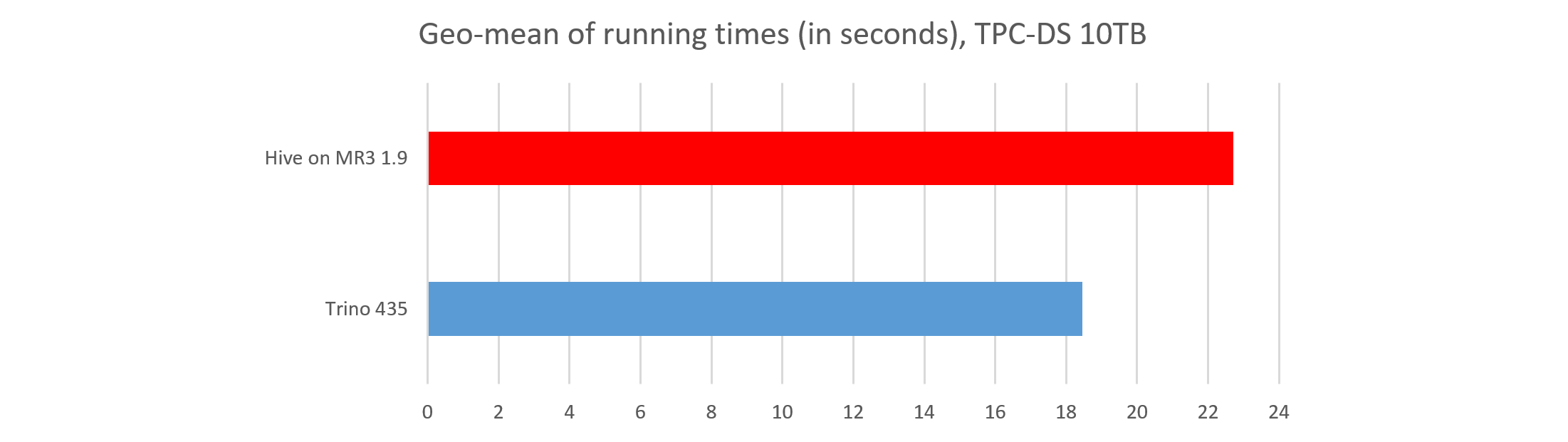
#4. Response time
In terms of the geometric mean of running times, Trino responds 23 percent faster than Hive on MR3.
- On average, Trino finishes each query in 18.45 seconds.
- On average, Hive on MR3 finishes each query in 22.70 seconds.
Conclusion
Hive on MR3 1.9 has achieved a substantial improvement in performance over Hive on MR3 1.7. The shorter running time and the faster response time can be attributed to three key factors:
- The new datasets use Snappy compression instead of Gzip compression, with Trino also benefiting from this change.
- We have adjusted the default configurations for Metastore and HiveServer2.
For example, Metastore provides more accurate column statistics
by setting the configuration key
metastore.stats.fetch.bitvectorto true, and MR3 avoids aggressive auto parallelism in order to reduce the response time for sequential queries. - MR3 incorporates several new optimization techniques. For example, it fully leverages free memory in Java heap to store intermediate data shuffled from remote nodes, thereby minimizing writes to local disks.
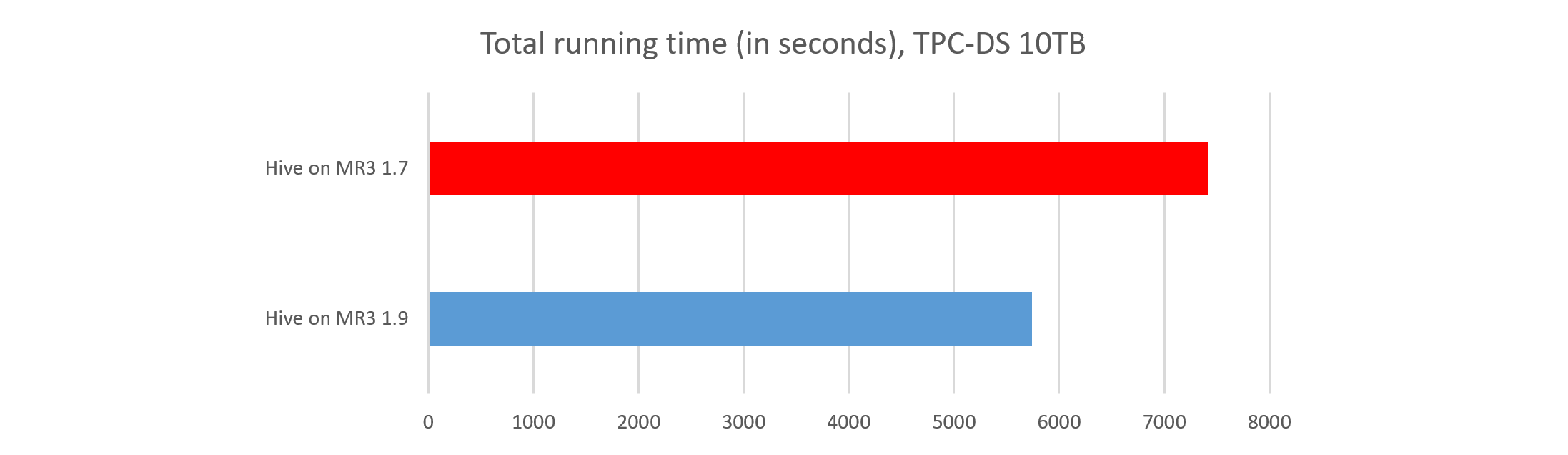
Trino 435 also runs significantly faster than the earlier version Trino 418. Two challenges persist, however: a scalability problem (query 72) and a correctness bug (query 23). The latter is particularly concerning because incorrect query results could lead to misguided business decisions. We believe that this correctness bug was introduced after PrestoSQL was rebranded as Trino, as Presto 317 returns correct results for query 23.
If you are interested in Hive on MR3, join MR3 Slack or see Quick Start Guide.